Содержание
Сегодня поговорим про Zen3, к сожалению каких-то тонких подробностей об изменениях микроархитеткуры AMD ещё не поведали, так что остается довольствоваться только тем, что было на презентации.
Но для того чтобы рассказать про отличия надо вначале рассказать как это вообще все работает.
Как работает конвейер в современных AMD процессорах
Напомню, что на сайте есть отдельный материал про Zen2 и отличие его от Zen+ где подробнее рассказана работа процессора.
Очень коротко напомню суть.
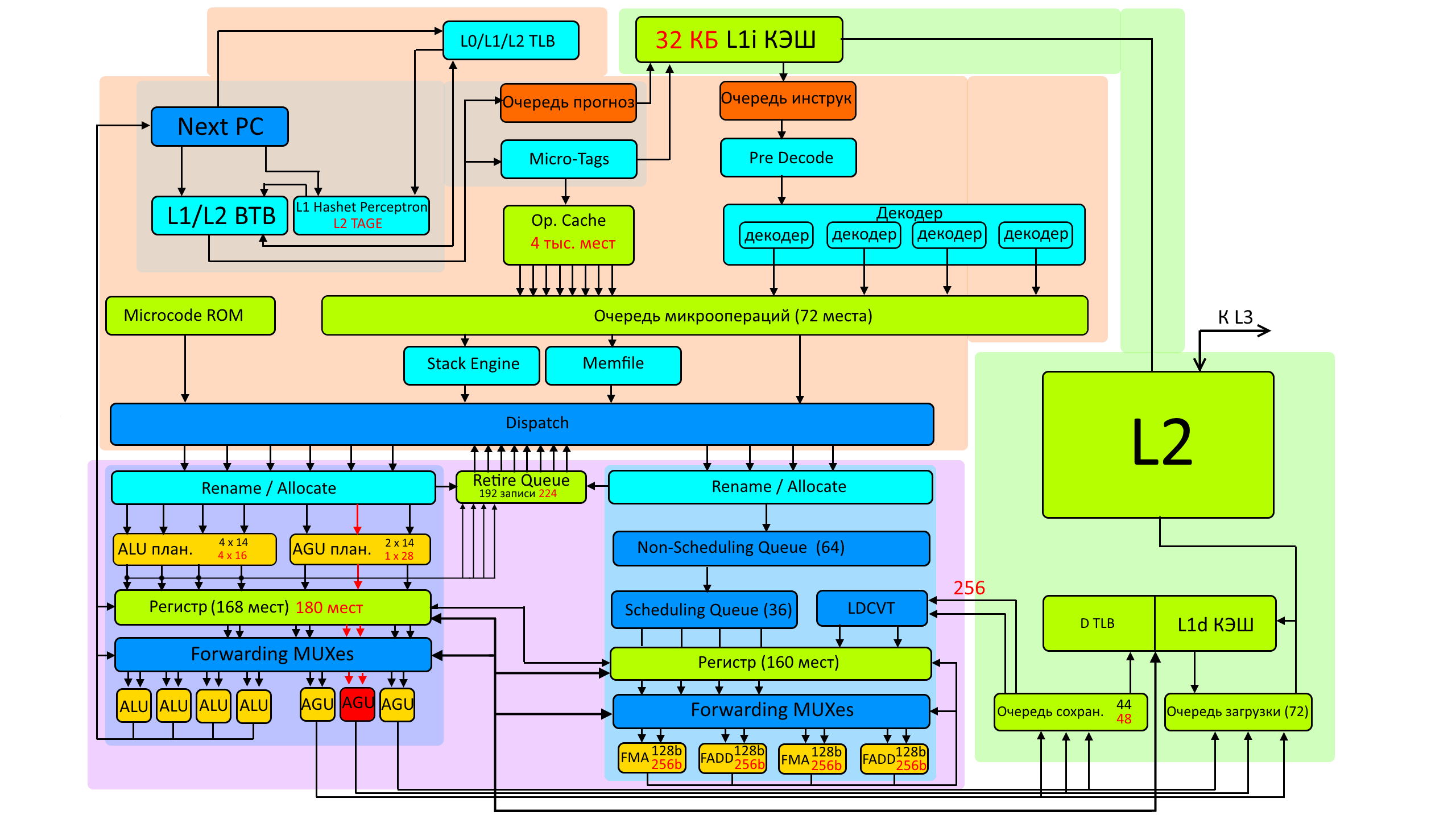
Суть в том, что в AMD в ядрах есть две зоны для исполнения микроопераций.
Одна для целочисленных операций,

вторая для операций с плавающей точкой.

И чтобы выполнить эти операции процессор должен в эти зоны исполнения передать сведения о самой задачи, то есть что делать и с чем надо что-то делать. Этим занимается конвейер процессора в верхней половине схемы. Микрооперации в очередь поступают из двух направлений — первое направление — декодер.

Второе — кеш микроопераций, куда помещаются прошлые уже декодированние микрооперации.

Далее из этих двух источников микрооперации формируются в единую очередь

и разделяются уже на две области — для целочисленных вычислений и вычислений с плавающей точкой где свои планировщики в свои регистры формируют уже финальные очереди для передачи микроопераций на выполнение, с другой стороны — при поступлении микроопераций на выполнение из кеша должны прийти значения для используемых операндов. То есть конкретные цифры с которыми надо выполнять те или иные операции.
Кроме того особняком от основного конвейера существует ещё одна область, которая имеет доступ к результатам вычислений, кешу микроопераций и кешу инструкций и она выполняет задачи предсказания переходов и ветвлений без непосредственного определения какие в реальности нужны переходы и ветвления с последующей проверкой правильности предсказаний.

И ещё раз напомню, что это схема Zen+ и Zen2 в которой красным выделено то что появилось только в Zen2, а AMD представили сейчас Zen3.

Ну и теперь переходим к тому что AMD рассказали про Zen3.
Откуда прирост в Zen3?

Первое что стоит отметить, что AMD заявили о приросте в 19% выполняемых инструкций за такт.

В эти 19 включены совокупно все изменения в микроархитеткуре, и к сожалению не указано что именно менялось.

В целом — чистая теоретическая производительность определяется только исполнительными блоками.

Это вот эти жёлтые штуки, в которых встречаются микрооперации и данные для них и происходит исполнение микроопераций.
Очевидно, что увеличив их количество на две штуки мы и получим те самые 19%. Но так как 19% взяты не только исполнениями, а совокупно, то очевидно, что два исполнительных блока добавлено точно не было. Более того, не было заявлено об увеличении теоретической производительности для вычислений с плавающей точкой или целочисленных. Допустим в Zen2 AMD для вычислений с плавающей точкой заявили двукратный прирост производительности для вычислений с плавающей точкой.

Сказали они это из-за того что раньше 256 битные инструкции делились на два такта, а с Zen2 исполнительные блоки стали 256 битными. В этот раз — никаких ускорений для вычислений не заявлено.
Но заявлено увеличение производительности в чтении и записи. Так что на основе сказанного наиболее вероятно, что вслед за одним новым AGU в прошлом обновлении AMD добавили ещё один, либо заявленные улучшения связаны с изменением логистических особенностей процессора, так как формально части связанные с работой с данными относятся к целочисленной ветви конвейера процессора.

Intel в «тигер лейк» в общем-то сделали примерно тоже самое, то есть добавили портов именно для работы с данными, а не для вычислений, которые были расширены по сути новыми 512 битными инструкциями без изменения ширины по числу портов.
Кроме того в AMD рассказали о некой гибкости в выполнении целочисленных и операций с плавающей точкой. Не думаю, что AMD отказались от деления конвейера на два пути, это тот путь, который AMD выбрали слишком давно чтобы от него было просто избавиться, да и в общем-то никто не говорит, что он не правильный.

Возможно теперь процессор ещё более динамически может выделять место в регистрах между целочисленной и дробными записями. опять же — возможно как-то изменились логистические пути для данных, устраняющие строгое деление конвейера.
В AMD также устно было заявлено о расширении поддерживаемых инструкций. Эта фраза несколько спорно звучит, так как вроде непосредственно никаких новых инструкций процессоры поддерживать не будут. Вероятнее всего, но это не точно, часть показанных тут на схеме ALU имеют те или иные ограничения по поддержке выполнения тех или иных микроопераций и возможно эти ограничения поменялись, благодаря чему процессор становиться более гибким в формировании очередей выполнения и более эффективным в реальных задачах.
Кроме того заявлены некие изменения в части предсказаний. Для современных процессоров это одна из самых сложных и важных областей и она довольно сильно влияет на реальную производительность.
На слайдах эти изменения в кавычках ещё названы “Zero Bubble” (перев. «Ноль пузырей»). И называется это так не спроста.

Дело в том, что вы видя схему понимаете, что от поступления задачи до её выполнения процессору надо сделать много разных действий.

То есть каждая задача должна пройти определённый путь от начала до конца, и ступеней этих довольно много. То есть если следить всего за одной операцией из-за того что ступеней много — на выполнение каждой операции нужно несколько тактов.

Но так как процессор перемещает операции на всех ступенях, то это выглядит, как люди на эскалаторе, они заходят, какое-то время едут, и потом сходят с него.

Но если измерять пропуснкую способность эскалатора, то видно что на него постоянно заходят люди, и с него постоянно сходят люди. так же и конвейеры процессора. Они бывают сложные и длинные, бывают простые и короткие. И так же как и в эскалаторах пропускная способность при прочем равном может поменяться только если вдруг люди перестанут занимать ступени с расчётной плотностью. То есть если вдруг кто-то не встал на ступень, то по эскалатору поедет кусок пустоты. Иными словами — пузырь.

Так же и с процессорами — если процессор не смог в какой-то из тактов в самом начале в достаточной мере использовать все свои возможности, то с каждым тактом спускаясь по конвейеру эта пустота волной пройдёт через весь конвейер и именно эта пустота и количество этих пустот влияют на реальную производительность.

Естественно чтобы собирать эти пустоты и нивилировать их влияние существуют очереди, которые избыточны для имеющегося набора исполнительных устройств.

Очереди позволяют убирать пустоты, как буд-то эскалатор поделили на две части между которыми сделали площадку где люди заново могут уже более плотно занять вторую часть конвейера.
Но эти очереди находятся уже в середине конвейера, то есть они не смогут увеличить входную пропускную способность. Именно для симуляции увеличения входной пропускной способности нужен предсказатель и отчасти кеш микроопераций. Когда потенциально мог бы образоваться пузырь процессор всеми правдами и неправдами пытается этот пузырь чем-то занять. Если процессор угадал что-то в своих предположениях — то процессор молодец, он не допустил падение производительности, которое казалось было неизбежным. Правда если процессор оказывается не прав, то на платформу станции внизу эскалатора выходят правохранители, всех убивают кто зашёл на эскалатор после ошибочного, а так же убивают всех кто в текущий момент ещё едет по эскалатору.

Именно в этот момент очень важна длинна этого эскалатора. Для длинного эскалатора обнуление намного дольше будет приносить негативный эффект в производительности. Есть примеры когда очень длинный конвейер сыграл злую шутку для процессоров.

Так например pentium 4 имел 20 ступеней, то есть операции надо было пройти 20 тактов по конвейеру. Тогда как 3-ий Pentium и Athlon от AMD имели по 10 ступеней и именно из-за длины конвейера и бОльшего влияния обнулений — реальная производительность на такт у pintium 4 была сильно ниже, чем у третьего «пентиума» и «атлонов» (4-ые пентиумы имели при этом высокие для того времени частоты и сейчас бы эту частоту называли бы «кукурузной»).
Но мы возвращаемся к Zen3. AMD внесли некие изменения в часть отвечающую за предсказания, которая должна предотвращать появление пузырей в конвейере. И назвали этот комплекс изменений “Zero Bubble”.
Тем не менее было показано из чего состоят имеющиеся 19% прироста на такт.
«Макро» изменения в микроархитектуре
Но давайте отодвинемся от конвейера и рассмотрим процессоры целиком.
Как и с Zen2 они будут состоять из чиплетов.

Рдин из чиплетов заменяет северный и половину южного моста, то есть половину той штуки, которую мы на материнских платах сейчас называем чипсетом.

Судя по всему этот чиплет не особо поменялся, про него не было сказано ни единого слова.
А вот чиплеты с ядрами — изменились.
Ещё со времён первых процессоров на архитектуре Zen процессоры состояли из пары 4-х ядерных модулей, соединенных шиной Infinity Fabric.
Начиная с Zen 2 старшие процессоры на AM4 стали содержать два набора пар 4-х ядерных модулей. То есть уже в сумме 4-ре 4-х ядерные модуля.

Проблема с ними заключается в том, что они могут обращаться только к своему кешу L3. Что создаёт сложности когда одна задача распаралеливается на разные 4-х ядерные сборки. То есть, допустим, процессор решает какую-то задачу, а решение этой задачи нужно другому ядру в другом модуле. И приходиться эта данные передавать в другой модуль. Образуются дублированные записи, куча устаревших записей за которыми надо следить. Отдельная головная боль — игры. Дело в том, что многопоточность в играх — штука капризная. Часть задач реально можно распаралелить, Но далеко не все, вернее многие можно, но все, что хорошо параллелиться с каждым годом всё сильнее и сильнее отдаётся на вычисление видеокартой, а процессору остаётся всё то, что параллелиться плохо. Поэтому зачастую для игры важны моменты синхронизации потоков. То есть в какой-то момент поочерёдно ядра уже заканчивают свою часть работы, условно до некого чек пойнта где нужно синхронизировать результаты с другими ядрами и в итоге все ждут одно которому досталась самая сложная задача, к слову динамические бусты процессора как раз и должны за считанные такты выявлять такие вот ядра и передавать им весь TDP, над этим активно работает и intel и AMD.

Но с разделением на блоки там и так все ждали и простаивали, так ещё потом начинаются ещё и синхронизации кешей через несколько уровней инфинити фабрик.

Всё это только увеличивает задержки и простои до того как процессор вновь сможет начать следующие вычисления.

Поэтому пусть у процессоров Zen2 и высокая производительность на такт и в Cinebench они обходили intel на микроархитектуре Skylake, но в играх из-за лишних простоев — процессоры не могли быть столь же эффективными как intel с общей кольцевой шиной.
Естественно межчиплетный кеш у процессоров так и будет разделённым, но внутри чиптела у Zen3 теперь весь кеш L3, а это целых 32 МБ, общий на все 8 ядер.

То есть проблема сильно уменьшается. Скорее всего задержки самого кеша L3 чуть увеличатся, так как не меняя иерархию памяти от увеличения объёма — увеличиваются задержки на обращение к нему. Но если сравнивать с реальными задержками учитывая и Inter-core data Latency, то естественно задержки сильно снизятся, что и принесёт прирост производительности в играх, а так же в софте который очень активно работает с подсистемой памяти, это и системы работающие с данными, а также софт для вычислений и многие другое.
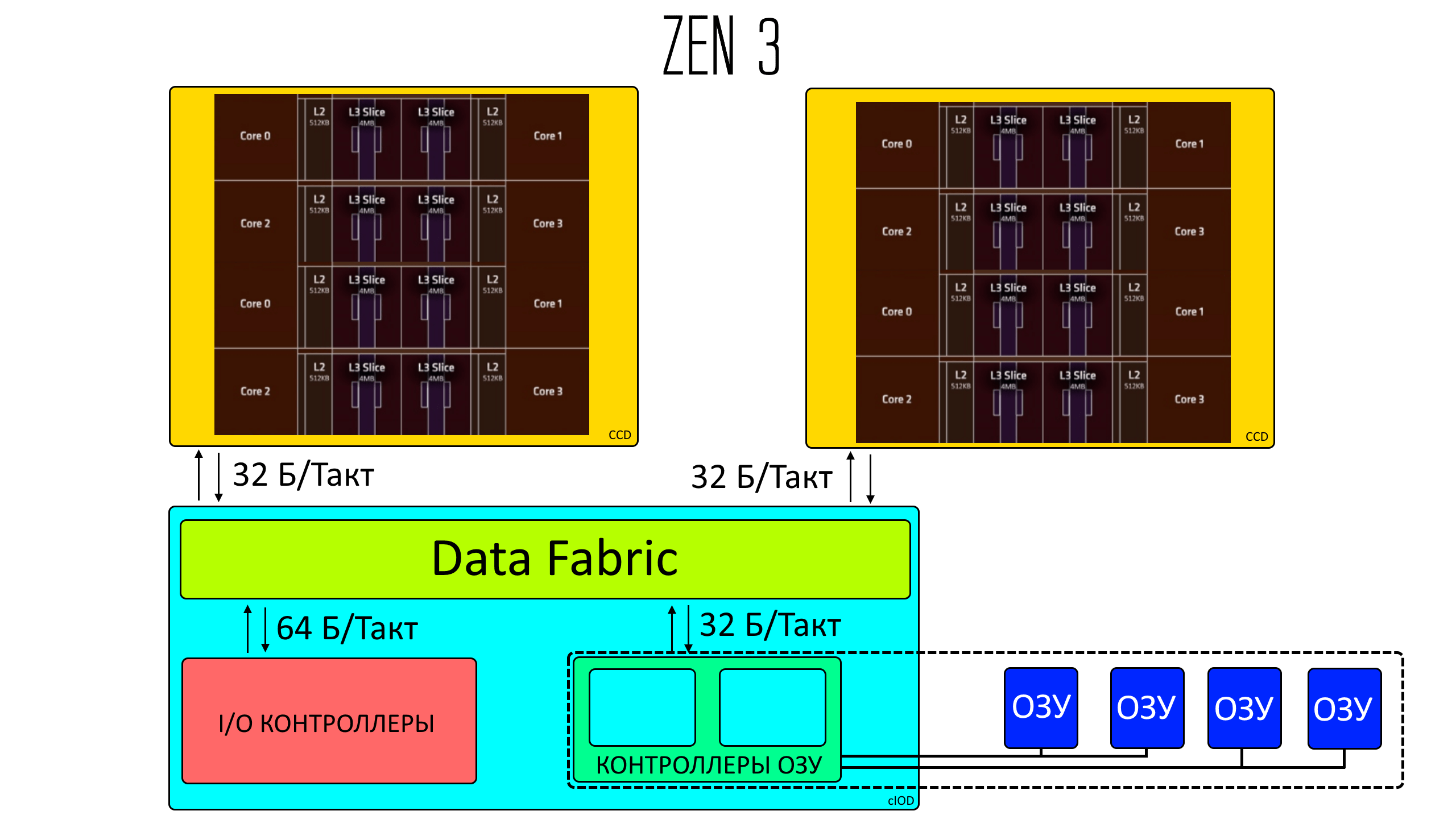
Остаётся, конечно, вопрос, зачем вообще AMD в самый первый Zen ввели это деление. Скорее всего где-то между всякой строительной техникой типа бульдозеров и экскаваторов и Zen у AMD были какие-то промежуточные разработки, хвосты которых добрались до микроархитеткуры Zen, возможно с мыслями об упрощении масштабирования, но только сейчас эти рудименты AMD отрубили. Скучать по ним мы, конечно же, не будем.
Как изменения сказались на практике?
Ну и теперь перейдём к тому что AMD показали на практике.
Естественно стоит учитывать, что показанные цифры — это то что показала сама компания, то есть это не независимые тесты и выборка скорее всего предвзятая, для того чтобы показать продукт с лучшей стороны.
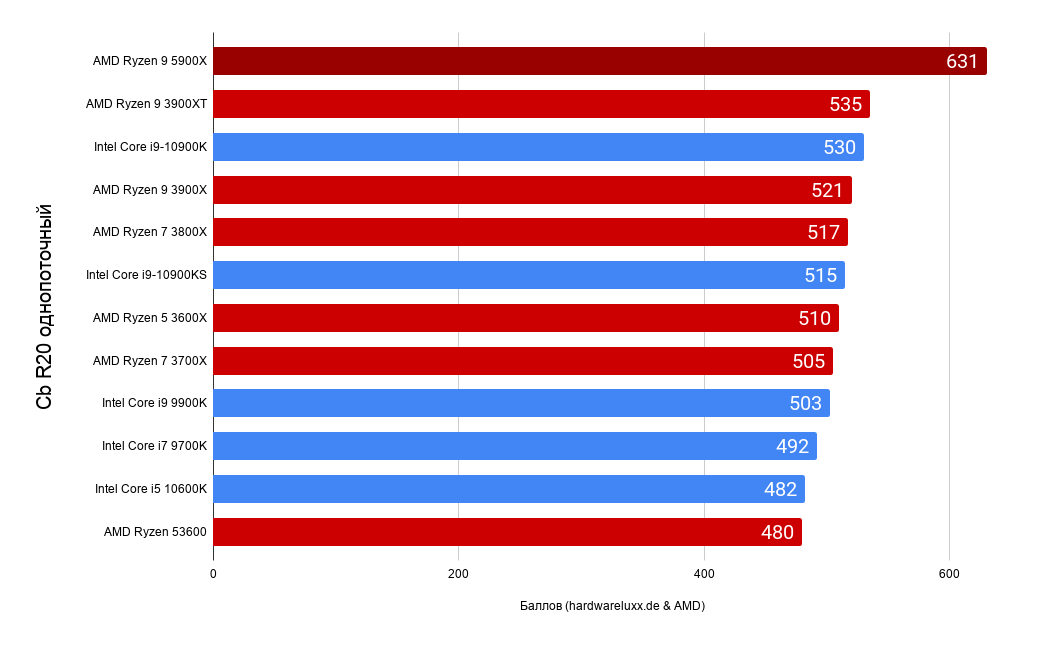
Что касается производительность на такт, то AMD показали результаты одного потока в сенбенч R20.

12 ядерный R9 5900X на один поток показывал 631 балл, сравнили AMD свой продукт с i9 10900k и ему дали 544 балла, а словами называли цифру о том, что у него около 530.
В этом сравнении, естественно не хватает данных о Zen2.
В качестве данных предлагаю взять результаты с сайта Hardwareluxx.

Используя эти данные и данные от AMD из презентации получается вот такая диаграмма. Прирост очень уверенный, и очень сильно превышающий показатели текущей intel платформы.
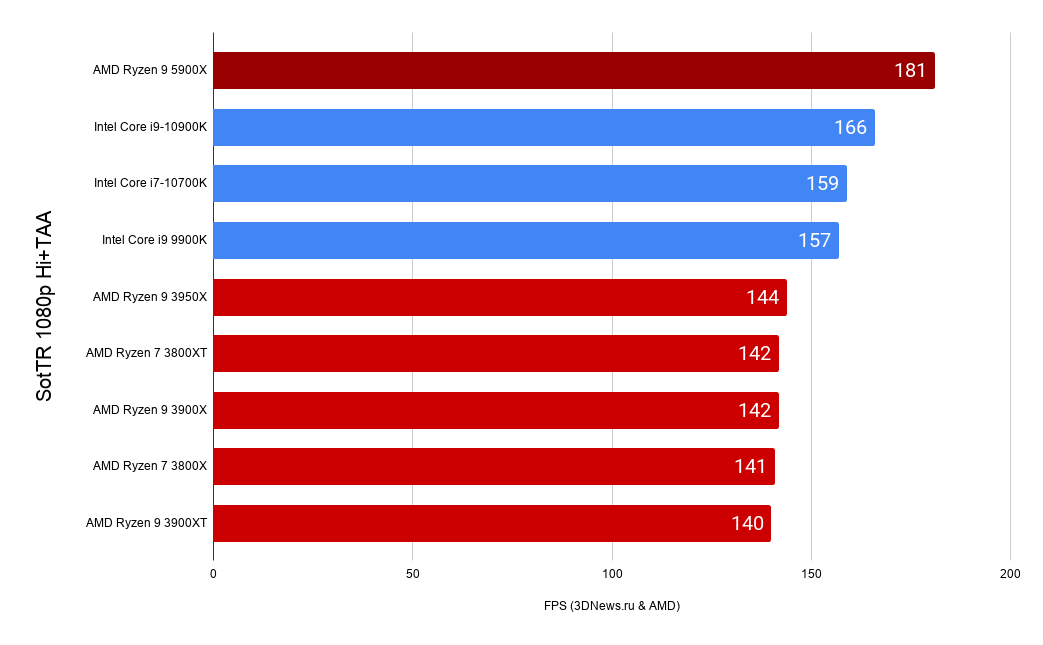
Из игр — в основном были показаны только соотношения, а не конкретные цифры.
Цифры были показаны только для одной игры — Shadow of the Tomb Raider.

Для 12 ядерного Zen2 141 FPS, для 12 ядерного Zen3 181 FPS.
Опять же — не хватает сравнений с intel.
Для этого сравнения воспользуемся уже данными с 3D News где 12 ядерный Zen2 набрал 140 FPS, что довольно близко к заявленным 141 FPS.

i9 10900k у редакции 3D News показал результат 166 FPS.
В общем — если AMD нас не обманули, то мы и вправду увидим нового короля для игровых десктопов.
И конкретно в этот раз у меня нет поводов считать, что AMD обманули. В прошлые года компания рассказывала про какие-то там паритеты в 1440р и тому подобные вещи в играх. Которых в реальности не было. Но сейчас есть один очень важный аргумент в польщу того, что это всё не обман и новые процессоры действительно будут лучшими для игр. И аргумент этот — цены.
По чём будет продаваться?
AMD будет продавать свои процессоры с равным количеством ядер дороже, чем intel. Было бы глупо пытаться продавать продукт с худшими характеристиками дороже конкурента. intel так пару последних лет делали, и получалось у них это не так чтобы очень хорошо, и то во многом только из-за игр.

6 ядерный 5600X будет иметь рекомендуемый ценник — 300 долларов. Старший 6-ти ядерник от intel — 260 долларов.
8 ядер от AMD — 450 долларов, старшие 8 ядер от intel около 380.
12 ядер от AMD — 550 долларов, 16 ядер — 800 долларов. У intel нет аналогов для обычной платформы, но 10 ядер intel оценивает в 500 долларов.
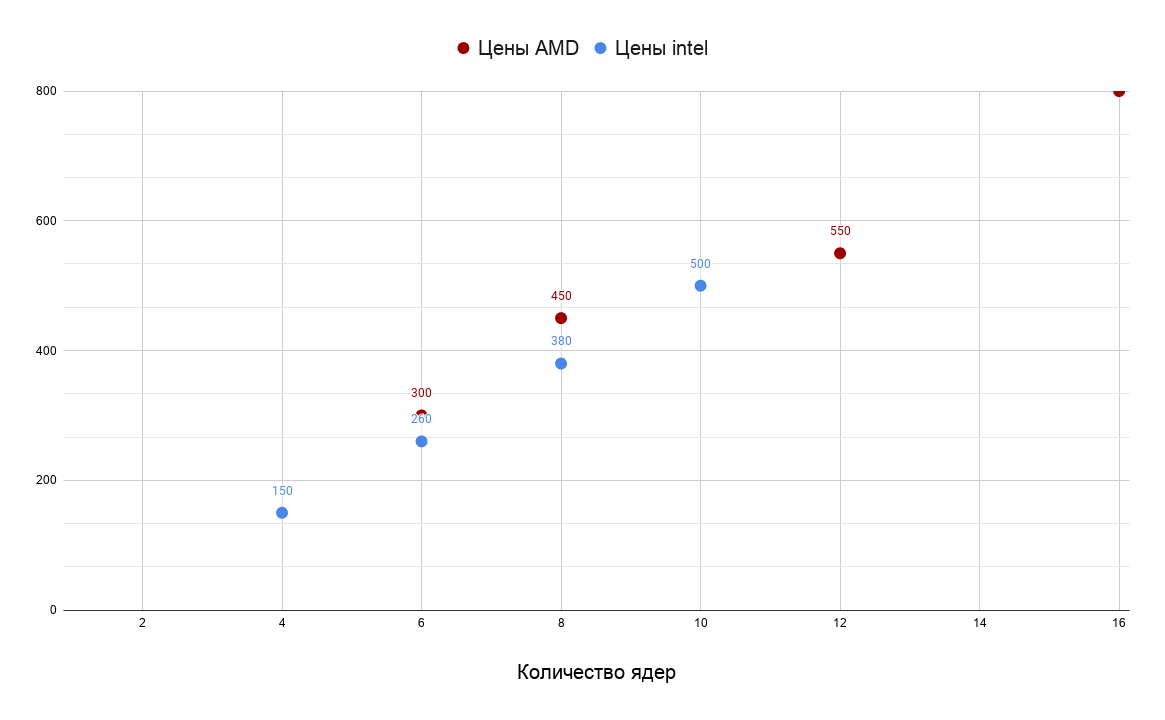
Именно ценовая политика явно указывает на то, что AMD ничуть нигде не обманывали, а сделали лучший на текущий момент процессор с x86 совместимой архитектурой. Другой вопрос, что через несколько месяцев intel на это ответит первым обновлением микроархитектур для настольных процессоров со времён скайлейка представив процессоры на основе Willow Cove. Отобъёт или нет intel себе обратно титул лучшего игрового процессора покажет время, но в любом случае — верхний предел ценников для текущей платформы у intel сможет подняться до ценников AMD, если процессоры будут не хуже, чем у AMD.
Что касается выхода процессоров, которые AMD отнести к пятому поколению, то появляться они начнут в ноябре.
Касаемо материнских плат сокет остался прежним — AM4. Обещана поддержка процессоров платами с чипсетами X570 и B550. Свежие биосы на них выйдут в ближайшее время.
В начале следующего года будут доступны обновления биоса и для плат с чипсетами 400 серии. Но введение поддержки будет на усмотрение производителей матринских плат, то есть не факт, что все платы с чипсетами 400-ой серии получат поддержку новых процессоров.
 Подписаться на канал
Подписаться на канал

На самом деле, очень хотелось бы увидеть тесты Zen2 и Zen3 на канале. Как и тесты Rocket Lake в будущем. И не просто сравнение цифр, а анализ того, как изменения микроархитектуры на что повлияли. И дело тут не в актуальности тестов для выбора железа. Канал, думаю, смотрят в первую очередь в образовательных целях. В этом плане тесты точно не устареют.
Сами по себе оперативные тесты новинок много кто делает, и в русскоязычном сегменте, и, тем более, в англоязычном. Тут канал и так не сможет быть конкурентом, как мне кажется. А вот на глубокий анализ причин изменения производительности способны немногие.
lga1200/am4 — это в 2021 халифы на час/6-9 месяцев, ибо на носу 5nm/pci-e 5.0/ddr5/ на платформах lga1700/am5. У кого есть сейчас в наличии любое коріто от 2500к/8гиг ддр3 и ЛУЧШЕ — сидите на ..опе ровненько еще 1-2 годика и потом берет на выбор ту платформу, которая по душе. Сейчас покупать лютый оверпрайс о обоих — себя не уважать, тем более учитывая тотальное обнищание и неопределенность во всем.