Содержание
Intel уже представили 11 поколение своих процессоров, которое назвали Tiger Lake. В скором времени они уже появятся в ноутбуках, они получили новый техпроцесс SuperFin, он же второе поколение 10 нм от intel, который даст лучшую энергоэффективность при больших токах, равно как и частотных нагрузках, а также меньшие напряжения для стабильной работы.
Но сайт у меня ноутбуков практически никак не касается и казалось бы: зачем тогда я про это рассказываю? А рассказываю я про это потому, что в поколении Tiger Lake применяются ядра с микроархитектурой intel Willow Cove.
И именно на этой микроархитектуре выйдут следующие настольные процессоры intel.
Единственное выйдут они не на втором поколении 10 нм, а на каком-то по счёту поколении 14 нм.
Но суть не в нанометрах. Нанометры — это, конечно, хорошо, но главное это то, что это станет первым изменением микроархитектуры ядер для настольных процессоров intel с 2015 года. Все процессоры с 6-го поколения у intel выходят для настольных компьютеров с одной и той же микроархитектурой Skylake.
Как работает конвейер процессора
Вообще на сайте уже есть материал про архитектуру Sunny Cove, а вернее её сравнение со Skylake. Willow Cove имеет от Sunny Cove очень маленькие различия, так что сейчас придётся немного повториться. Но сейчас ещё раз кратко пройдёмся по отличиям.
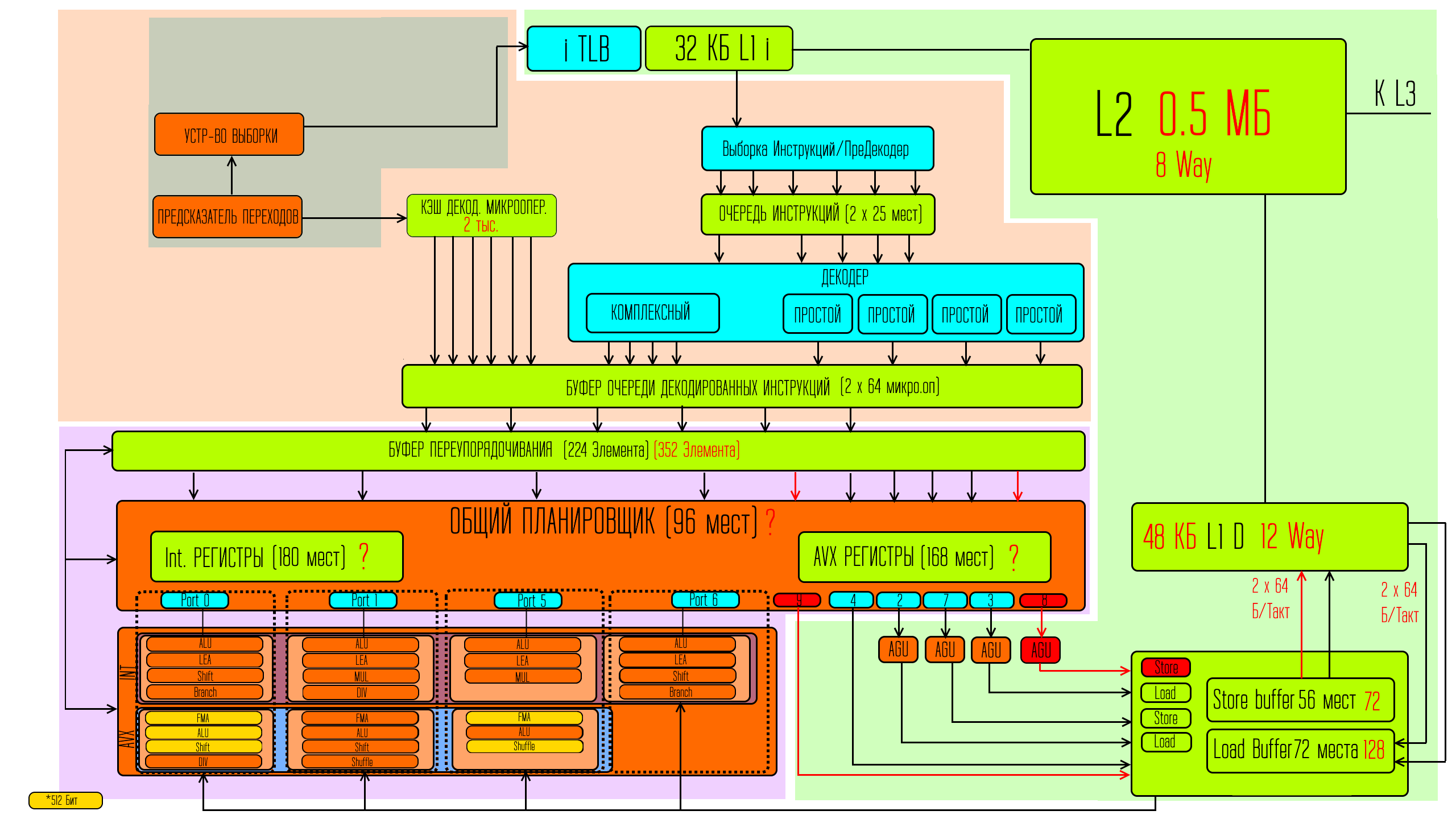
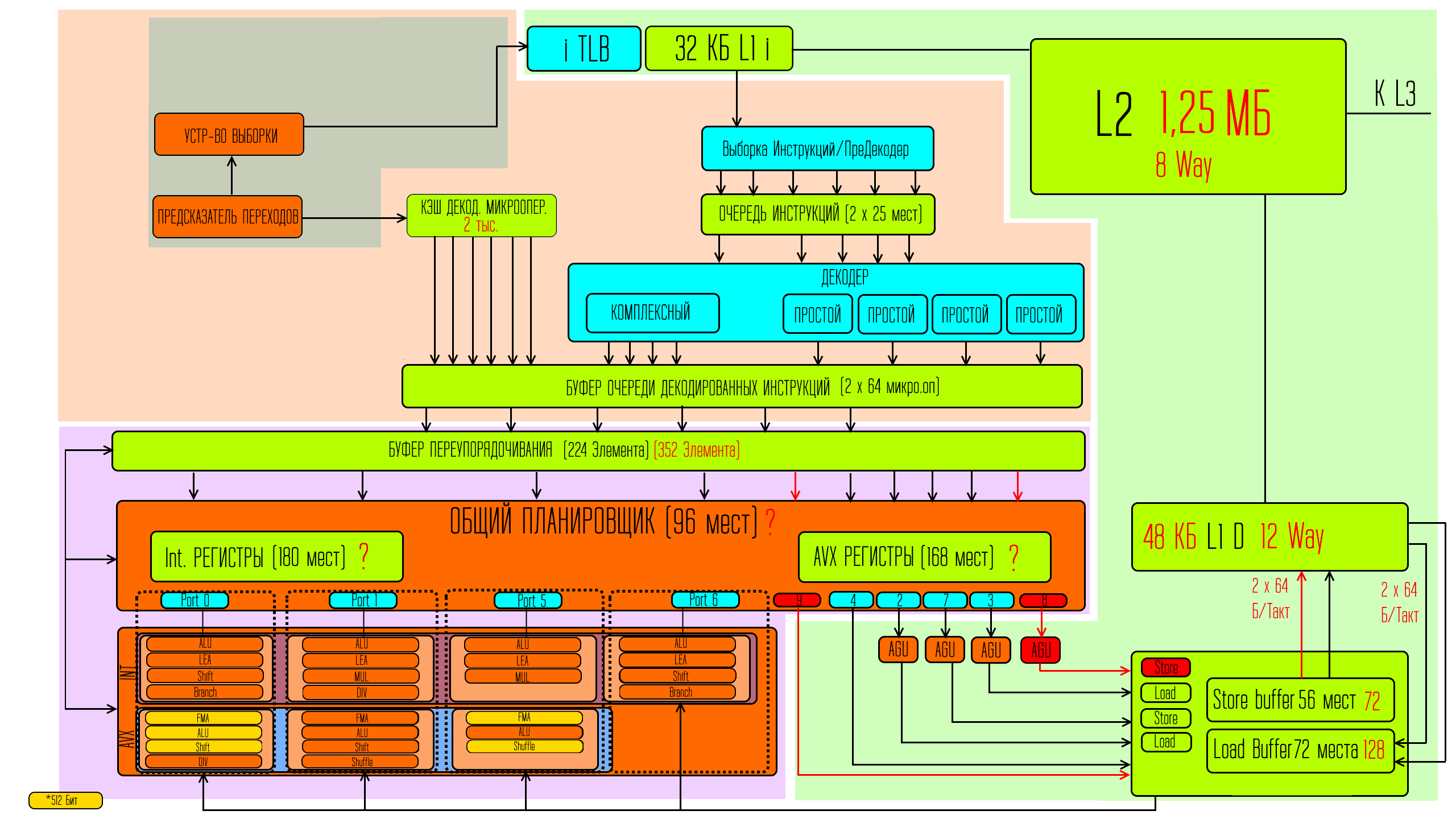
Опять же для начала я должен познакомить вас со схемой ядра и вкратце рассказать как это работает. Иначе не имеет смысла рассказывать о том, что было изменено.
У нас тут есть три глобальные зоны — зелёная

— это зона которая отвечает за хранение и перенос данных, зона свинячего цвета

— это зона отвечающая за работу с инструкциями, то есть цель этой зоны — организация выполнения задач процессором. Касаемо этих двух зон — представьте, что вам надо сложить» а» и «б». Свинячья зона отвечает за то, чтобы процессор понимал что ему надо делать складывание, а не что-то другое, и что это складывание надо сделать с «а» и «б». А задача зелёной зоны — обеспечить процессор самими значениями «а» и «б». Обе эти зоны должны поставить свои части информации в процессор в фиолетовую зону,

где, собственно, само сложение и должно произойти на подходящем исполнительном устройстве для сложения.
Так как выполняет процессор разные задачи, то под эти разные задачи существуют и разные исполнительные устройства, но каждая из задач выполняет только на одном из них. Так же тут видно, что intel объединили эти исполнительные устройства в наборы по несколько штук. Доступ к каждому из наборов осуществляется через порт. В скайлейк этих портов было 8 штук.

4 из них служат для работы с данными, то есть обеспечивают получение данных и записи результатов.

А 4 порта соединены как раз таки с наборами исполнительных устройств.
При этом каждый такт работы процессора для максимальной производительности — процессору нужно передать для исполнения какую-то задачу на каждый из портов. То есть если не удаётся найти ни одной задачи, подходящий для одного из исполнительных устройств в наборе — то через порт задачи никакой не подаётся, а значит процессор выполняет меньшее количество инструкций за такт, чем может теоретически.
И это большая проблема. Вернее, наверное самая большая из всех, так как именно из-за неё теоретическая и практическая производительности не равны друг другу. То есть на практике — процессор не всегда может занять все свои порты каждый такт.
И для того чтобы не занятых портов на каждом такте оставались как можно меньше и существуют области зелёного и свинячего цветов.
Зелёной области надо лишь быть большой настолько, насколько это возможно по объёму, чтобы хранить как можно больше данных вблизи процессора с известными для процессора задержками, так чтобы эти данные можно было поставить для исполнения точно вовремя в нужное место.
А вот для свинячей области уготованы куда более сложные задачи.
Задача в том, чтобы перемешать входящие задачи так, чтобы каждый такт подбирать на выполнения такие, чтобы они занимали все порты процессора и достигалась наивысшая производительность.
Это как играть в тетрис, но только вместо одной фигуры за раз — падает сразу 8, и их надо собрать так чтобы каждый раз получалась цельная строка.
В общем — задача не из простых.
В реальном времени случайные входящие задачи так собрать и вовсе невозможно.
Поэтому перед выполнением формируются специальные очереди.
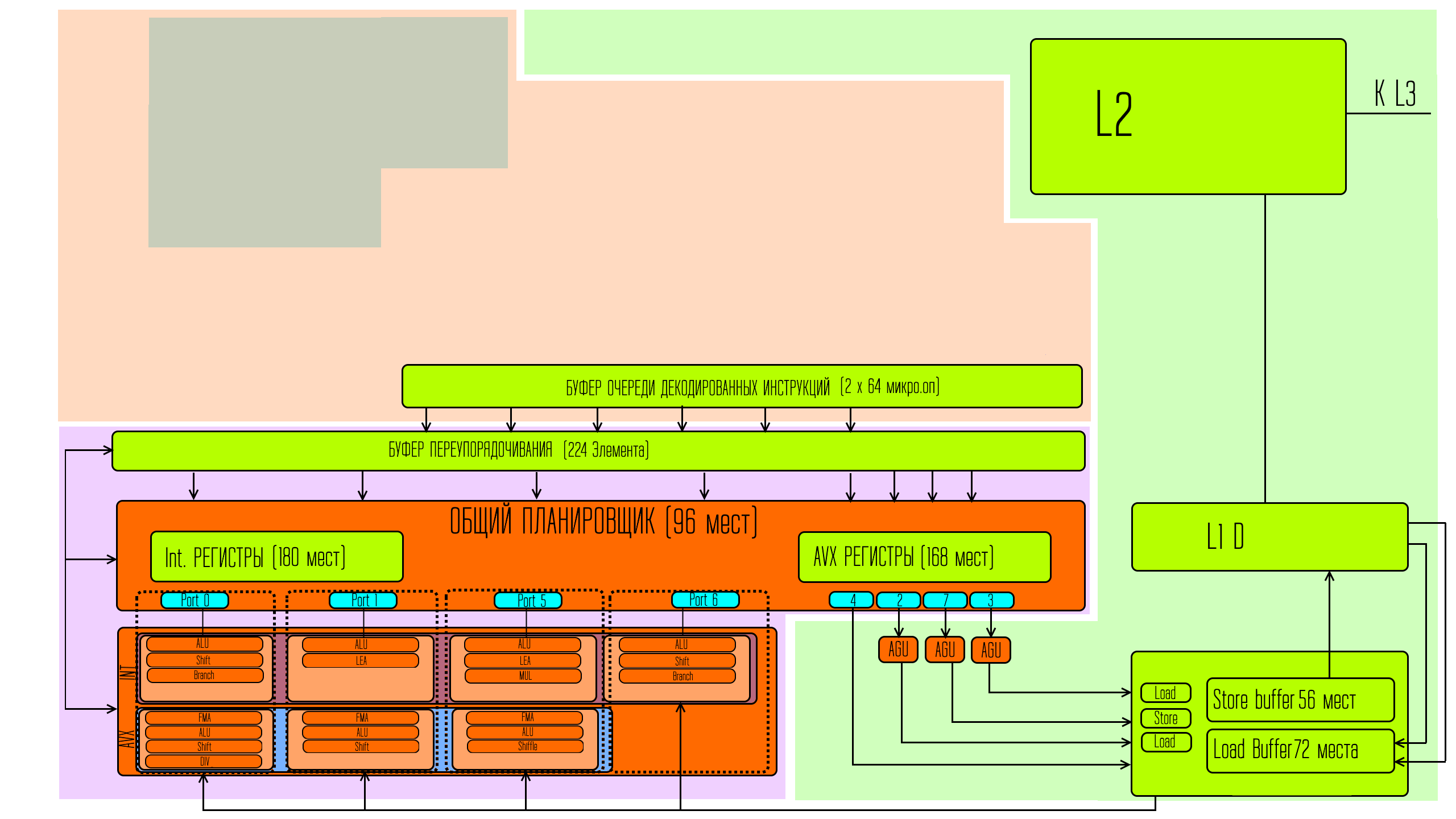
Если сравнивать с тетрисом — процессор получает не 8 случайных фигур при каждом падении, а выбирает среди несколько сотен разных фигур сам такой набор, который и будет максимально эффективным.
Но чтобы эта очередь из тех микроопераций, которые можно выбрать для выполнения формировалась — надо чтобы в эту очередь постоянно что-то новое поступало, ведь если процессор будет что-то постоянно забирать, то в итоге там ничего не останется.
И тут возникают некоторые сложности, обусловленные историческими проблемами.
Дело в том, что x86 архитектура задумывалась как некая относительно универсальная архитектура, способная выполнять довольно широкий набор команд. И со временем наборы поддерживаемых команд росли. И в какой-то момент времени их стало так много, что развивать процессор становилось всё сложнее и сложнее, а многие его части использовались слишком редко, и для тех которые нужны часто — оставалось слишком мало места.
Для решения этой проблемы intel оставили лишь формальную поддержку набора команд. То есть совместимость осталась, но не настоящая.
На входе этих команд процессор должен преобразовать их в ограниченный набор более простых микроопераций, которые и будет выполнять процессор.
Это всё происходит в свинячей части до формирования очередей.
И эта зона является сложной и ответственной. Уже в виде микроопераций в очереди поступают записи через декодеры, либо из ранее декодированных сохранений из специального кеша микроопераций.
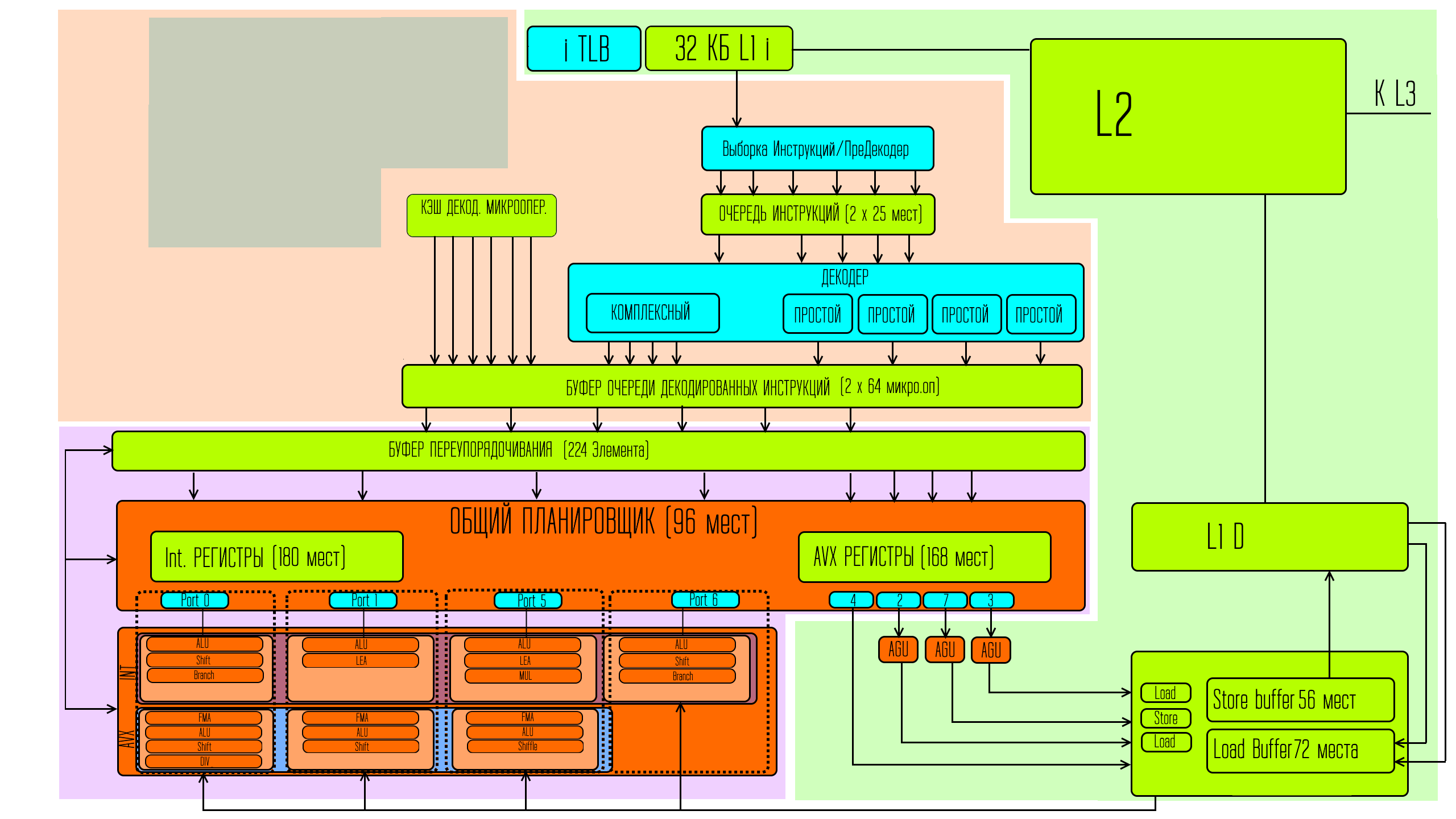
Кроме того процессор должен следить за тем, чтобы он мог выполнить эти микрооперации, то есть соблюдать последовательность, в которой не должны отправляться на исполнения те, результаты для которых ещё не известны, то есть условно — если есть выражение, что с = а+б, а чтобы получить «а» нужно для начала сложить б и д, то пока не посчитаешь «а» не сможешь посчитать «c». Если процессор не правильно соберёт последовательность — это будет проблемой. Кроме того иногда очерёдность зависит от выполнения каких-то условий. То есть если какое-то условие является верным — выполняется один набор микроопераций, а если условие неверно — выполняется другой набор микроопераций. И бывает так, что ждать данные для проверки условий, или для точного определения последовательности выполнения слишком долго. На этот случай у современных процессоров есть специальные блоки, которые на основе предыдущих выполненных условий делают предположения о том что и когда можно делать.
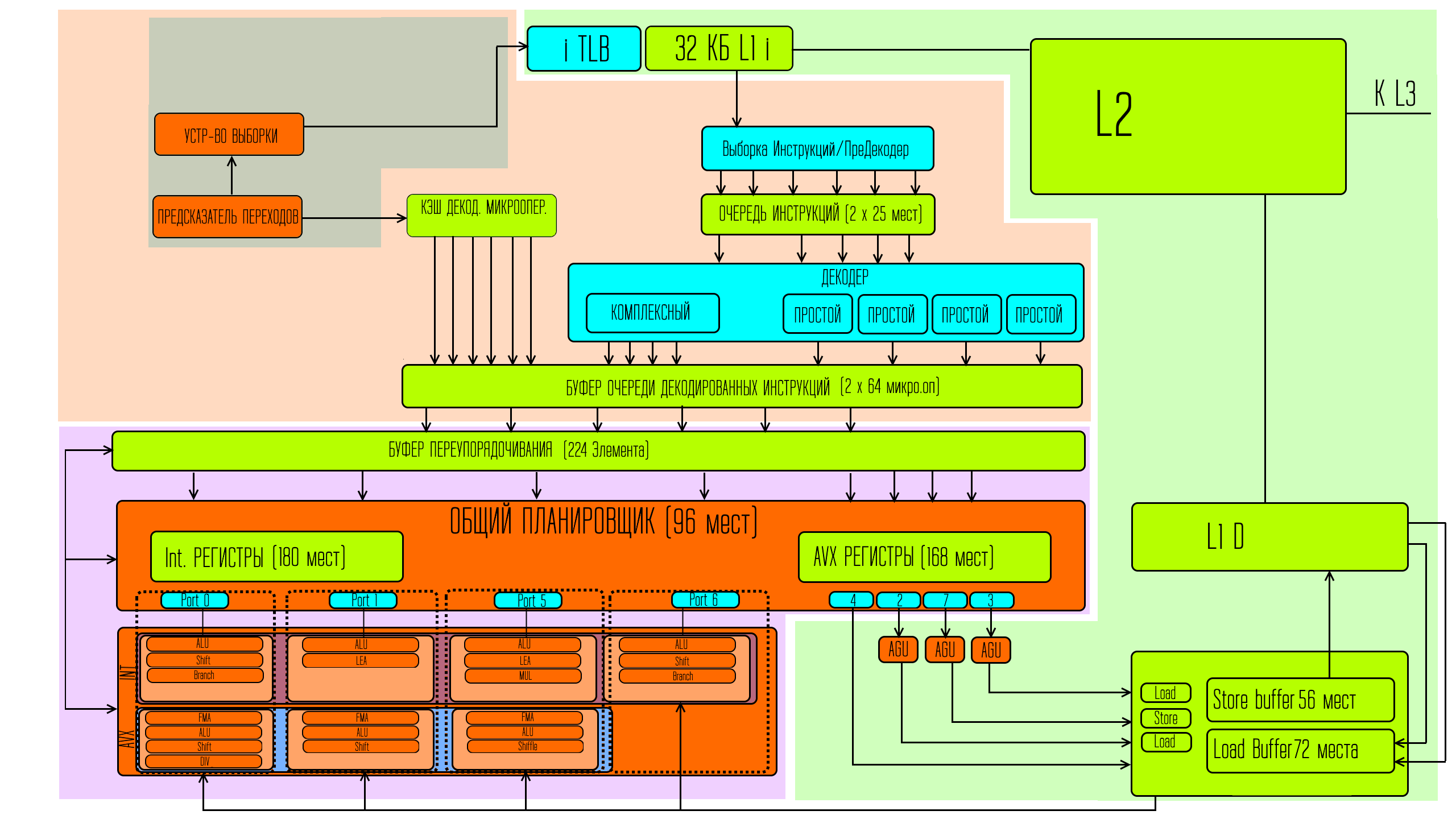
Естественно бывают и ошибки, тогда процессору приходиться сбрасиывать все результаты к точке этих предположений и считать всё заново. Дело это сложное и во многом определяет производительность современных процессоров. Зона эта у меня описана довольно скупо, и помещена внутри свинячей области в серую зону. А изначально ещё не декодированные команды поступают из кеша L1 инструкций.
И сейчас вам показана схема микроархитектуры процессоров скайлейк. Естественно на деле всё куда сложнее — но основные базовые блоки тут показаны.
Отличия микроархитектуры Willow Cove
Ну и теперь вернёмся к основной теме — к микроархитектуре Willow Cove и раберёмся, что в ней изменилось в сравнении со Skylake.
Во первых, как вы поднимете — зелёная и свинячья обвязка позволяют лишь приближаться к теоретической производительности, а сама теоретическая производительность обеспечивается исключительно сиреневой частью, так что начнём с неё.
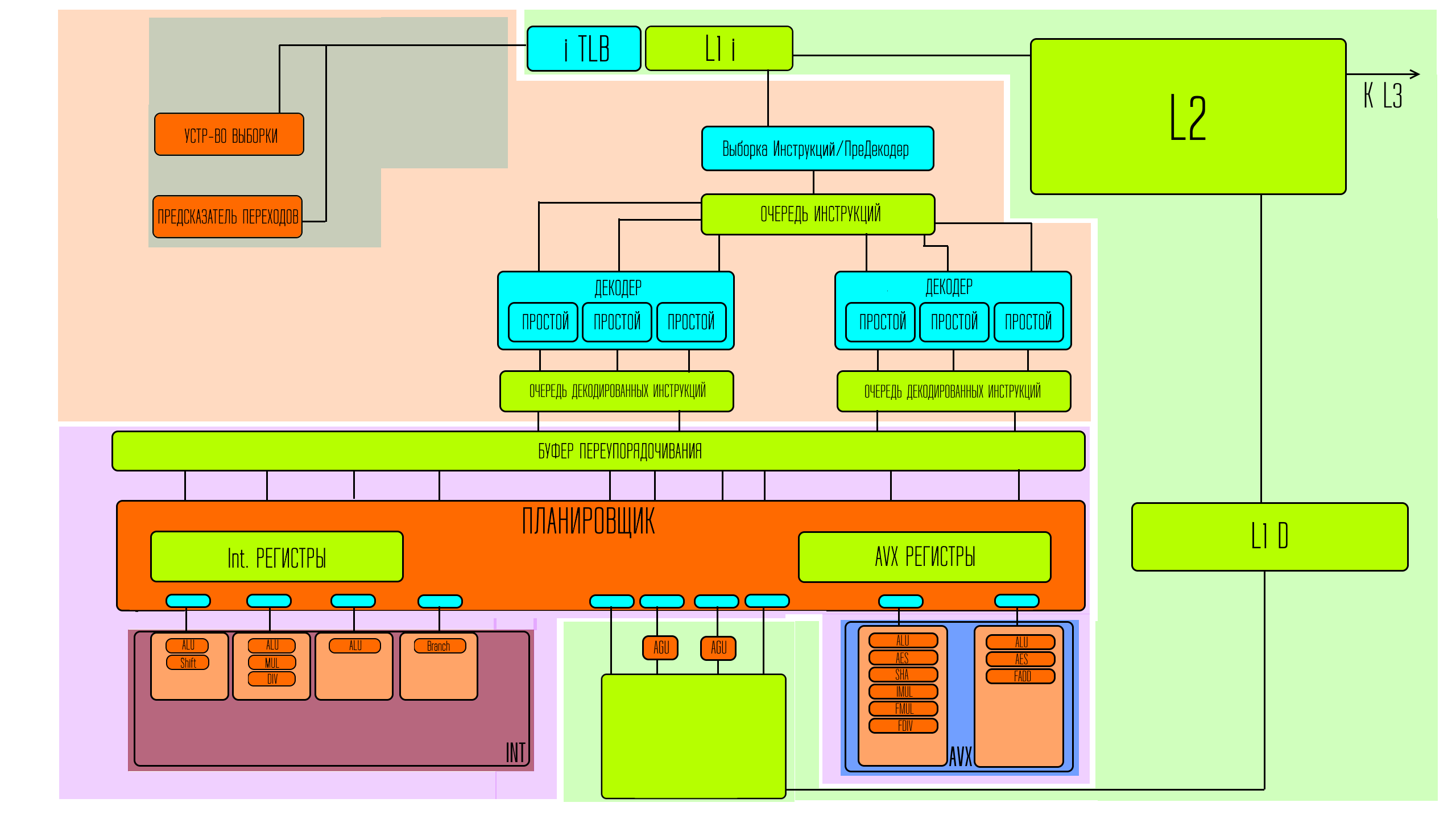
Intel изменили число портов с 8 до 10. Что и обеспечивает теоретический прирост производительности.

Новые порты не для наборов исполнительных устройств, а для работы с данными. Однако и с исполнительными устройствами всё несколько изменилось.
За каждым портом теперь находиться наборы с большим количеством исполнительных устройств, а это значит, что выбор передаваемых микроопераций так чтобы занимать все порты каждый такт становиться проще, а это значит, что пустующих портов в реальности в среднем по тактам станет меньше.

Кроме того в обычные процессоры были внедрены исполнительные устройства для 512 битных векторных команд.
Это даёт поддержку выполнения большого стака из однотипных операций за один такт. В том числе и для расчетов для нейронных сетей. На моём YouTube канале есть видео где я рассказывал о том, как устроены нейросети и в том числе показывал математическую интерпретацию расчётов.
Целые куски матриц можно запихивать в одну команду, что сильно упрощает декодирование этой кучи задач, а так же позволяет процессору понимать что надо хранить в регистрах дольше, а что — больше не понадобиться, что так же повышает реальную производительность, то есть делает её ближе к теоретической.
Естественно для того чтобы обеспечивать эти исполнительные устройства задачами — под их хранение надо больше, места. Так что увеличиваются объёмы регистровой памяти в планировщике, а так же в буфере переупорядочивания.

Кроме того для раскачки скорости декодирования, чтобы эта часть тоже соответствовала увеличившейся скорости выполнения был увеличен кеш микроопераций.

То есть процессор может для повторного использования хранить больше декодированных микроопераций, что снижает нагрузку на декодеры. Добавленные порты при этом сообщаются с буферами записи и загрузки также увеличенного объёма.

Кроме того — увеличился кеш L1 данных, а также удвоилась пропускная способность при общении с ним.
Значительно увеличился и объём кеша L2, с четверти мегабайта на ядро до 1,25 МБ. L3 тоже станет по 3 МБ на ядро вместо двух. Хотя, уверенности, что влезет столько кеша L2 и L3, как в мобильных представителях этой микроархитектуре у меня нет.
Всё же — мобильные процессоры на 10 нм, а настольные будут на 14. Плотность транзисторов ниже, а значит и кристалл при равной начинке — крупнее.
Если много кеша не влезет, то разгон памяти в новых процессорах будет очень важен.
Как можно увидеть — intel расширили сразу все критично важные зоны конвейера процессора. То есть улучшили не только ту часть которая исполняет задачи, но и обеспечили большей пропускаемостью и всю обвязку.
Это поднимет и теоретическую производительность на такт, и, вероятнее всего — реальную практическую.
Но это по сути пересказ старого материала про Sunny Cove, и Willow Cove.
Однако это только часть будущего процессора.
Как Intel конкурировать с AMD и гибридные процессоры
Дело в том, что Intel сейчас уже находиться в роли догоняющего. У AMD на обычную десктопную платформу есть 16 ядерные процессоры, а у Intel только 10. Если говорить про Zen2, в задачах требующих больших объёмов данных и не идеально работающих на большом числе потоков, в том числе и в играх — Zen2 пока не догнали intel. Но по абсолютной производительности решения от AMD уже далеко впереди. А дальше будет ещё Zen3, который будет ещё быстрее.
И intel надо что-то с этим делать.
Впихнуть 16 ядер intel не может по технологическим ограничениям, так что в будущих процессорах будет гибридная схема ядер. По крайней мере если верить слухам.
По предварительным данным — старшая конфигурация будет: 8 больших ядер, и 8 маленьких ядер.
Большие ядра, как вы понимаете, это те, о которых я рассказал выше.
Но и маленькие ядра intel тоже уже показали.
Intel Tremont
Официально не подтверждено, то что настольные процессоры будут гибридными и то что ядра с микроархитектурой Intel Tremont будут выполнять функции слабых ядер.
Однако других новых ядер у intel нет.
Поэтому если процессоры будут гибридными, то мы очень плотно столкнёмся с микроархитектурой Тремонд. А она тоже довольно интересна, потому что очень отличается от обычной.
К сожалению сама intel не представила данных о том каких размеров регистры, сколько помещается записей в очередях и тому подобное. Есть только вот это.
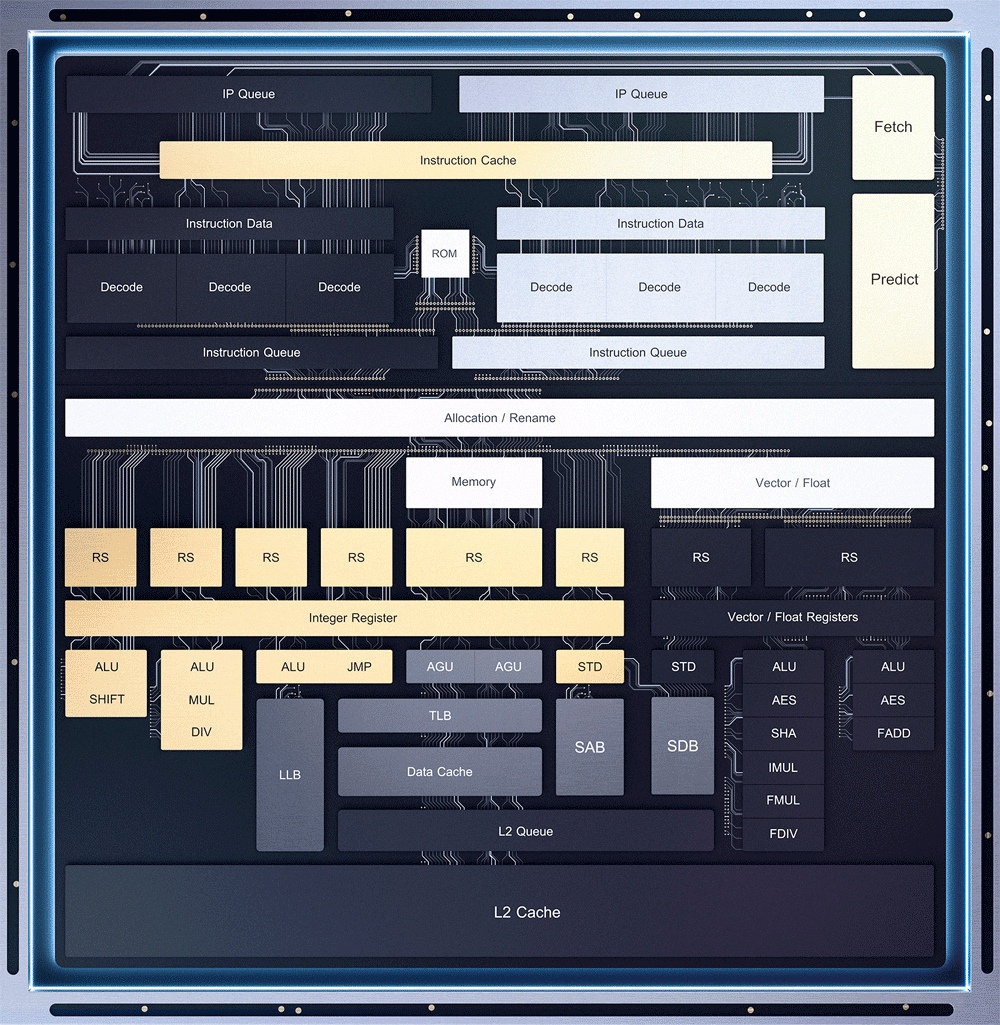
А видим мы тут очень интересную картину.
В обычных процессорах — за каждым из портов с исполнительными устройствами находятся и векторные устройства и обычные.


То есть процессору надо выбирать — либо больше выполнять векторных команд, либо больше — обычных.
В микроархитектуре тремонд — обычные и векторные исполнительные устройства разбросаны по разным портам.

С одной стороны — это позволяет не снижать производительность для обычных команд при выполнении векторных, с другой стороны — если векторных нет, то часть процессора будет просто простаивать. Вероятно intel на основе некоторой своей статистики решили, что доля векторных команд стала достаточно большой, чтобы выделить на них свои отдельные порты, а не совмещать их с обычными.
Возможно, если это окажется эффективным — в будущих микроархитектурах — intel на подобную стратегию переведут и большие ядра.
Так же мы видим, что intel ту часть что у меня была зелёной для работы с данными — поставили между обычными и векторными портами, визуально усилив разделение этих портов друг от друга, вдобавок выведя отдельными квардартиками регистры для обычных операций и векторных.

На самом деле эти регистры и так были раздельными. Но графически intel постарались разделить их ещё сильнее.
Тем не менее скорее всего суть осталась схожая, а часть отвечающая за работу с данными так же осталась общей для всех исполнительных устройств.

Видно, что осталось 4 порта для обычнх вычислений, сколько их и было, и добавилось два для векторных.
Но так же видно, что вариаций исполнительных устройств сильно меньше, чем у больших ядер. Что скорее всего сильно упрощает всю обвязку.
Кроме того intel заявляет, что полностью перенесла в Тремонт часть связанную с переопределением выполнения микроопераций и предсказатель ветвлений.

Однако есть и потери.
В тремонт нет кеша микроопераций, который в больших ядрах снижает нагрузку на декодеры.
А в качестве декодеров используются не 4 простых и один комплексный способный декодировать в 4 микрооперации, а пара блоков декодеров по 3 штуки в каждом.

То есть всего 6 микроопераций за такт, что меньше, чем у больших ядер в сумме из всех источников.
И это основные отличия ядер.
Ну и возвращаемся к тому, что настольные процессоры будут гибридными, соединяя в себе оба типа ядер.

Естественно если это всё будет запихано в один процессор возникают вопросы по тому как это всё соединить.
В целом — кольцевая шина прекрасно работает с разнородными устройствами и можно поместить на одну шину и 8 больших и 8 маленьких ядер.
Однако — чем больше адресатов на кольцевой шине у intel, тем она становиться менее эффективна.
Это работает так же как и кольцевые дороги в городах. Если вокруг МКАД поставить кучу торговых центров и крупные выезды на вылетные магистрали в которые всем надо ехать по МКАДу — жди больших пробок.
В этом плане — кольцевая шина тоже не резиновая. В прошлый раз её увеличили в два раза в Skylake. Учетверение количества ядер с тех пор слабо вяжется с тем, что шина это выдержит. А дальнейшее её расширение сожрёт всю площадь процессора.
Не исключено, что процессоры будут разъединены на два кольца, общаясь через кеш L3. По этому поводу intel, вероятнее всего, выдаст какие-то подробные материалы к выходу самих процессоров, но я бы не ставил на вариант с общей кольцевой шиной на 16 ядер.
Но в любом случае — вопрос подсчёта ядер станет довольно сложным. Потому что это и не 8 и не 16. Возможно придётся начать считать как-то по новому. Допустим раньше для одного ядра было для обычных инструкций 4 ALU, а будет для пары большой + маленький — в сумме 7 ALU.

С одной стороны — 7 — это и не 4, но это и не 8. Но на них будет два набора независимых планировщиков, а не так как было бы, если бы было 7 APU в одном ядре.
В общем — все нас путают.
Не так давно nvidia удвоив только число исполнительных устройств для FP32, не удвоив всё остальное — в спецификациях умножили в два раза число ядер. Стало ли в таком случае число ядер вдвое больше? Сложный вопрос.
В общем — все эти вопросы положим в копилку с FXами, где на два модуля для целочисленных вычислений было по одному с плавающей запятой.

4 в них ядра или 8 напрямую зависит от решаемых задач. В одних задачах их 4, а в других — 8.
Но, думаю, баталий по этому поводу будет не мало теперь и с Intel процессорами. А как будет на деле — покажут только тесты в реальных задачах.
 Подписаться на канал
Подписаться на канал

А откуда https://pc-01.tech/wp-content/uploads/2020/09/001-2048×1152.png эта картинка?
Вызывает вопрос
> кэш декодера микроопераций
Зачем микрооперации декодировать, они же уже представлены в целевом виде конкретной модели процессора. Может имеется ввиду кеш декодера инструкций?