Содержание
В материале на прошлой неделе я описал вам изменения в архитектуре процессоров Zen2. Сегодня же я предлагаю посмотреть на новую архитектуру intel, а именно архитектуру применяемую в процессорах Ice Lake, а сама архитектура называется Sunny Cove. Это архитектура включает в себя оба этапа обновлений, которые ранее intel называли «тик» и «так», то есть и улучшения литографии, и изменение архитектуры.

Ice Lake перешли на 10 нанометров. Процессоры эти, к сожалению, не появятся в настольных компьютерах и в высокопроизводительных ноутбуках. Возможно из-за того, что новый техпроцесс пока не способен обеспечить высокие частоты для процессора, как это было например с процессорами Broadwell на сокете LGA 1150 например. А возможно с частотами всё в порядке, но уровень выхода годной продукции столь низок, что intel продаёт кристаллы по себестоимости или вообще в убыток и в таком случае продажи процессора в массовом сегменте обернулись бы для компании крахом.

Более того — многие и сейчас не в курсе, что можно просто и спокойно купить в магазине себе ноутубк с 10 нм процессором intel. Причина этого в том, что не было официального срока начала продаж. Ноутбуки выходили просто по готовности, без громких презентаций и анонсов.
Ещё путаницы добавили и сами intel выпустив две ультрабучные линейки процессоров десятого поколения, Ice Lake, о которых и будет речь и Comet Lake, которые основаны на старой архитектуре и изготовляются на 14 нм техпроцессе.

Сравнение архитектур процессоров Intel и AMD
Далее мы рассмотрим основные принципы работы архитектуры Ice Lake, но для начала предлагаю коротко обозначить ключевое различие между процессорами intel и AMD, чтобы прочитавшим прошлый материал о Zen2 было проще сориентироваться. И так же как и с AMD — разница между новым и старым поколением intel процессоров не революционная, а эволюционная, то есть я вначале покажу схему архитектуры Skylake на которой строятся ядра процессоров с шестого по текущие поколения и по мере рассказа буду упоминать отличия.
Схемы intel и AMD чем-то на первый взгляд похожи, но на самом деле есть ряд фундаментальных отличий между архитектурами. В целом конвейеры intel и AMD имеют схожее функциональное деление. То есть вначале блоки связанные с кешем l1 инструкций где происходит декодирование команд в микрооперации, так же есть область предсказаний, так же далее по конвейеру микрооперации могут поступать и после декодирования и так же из кеша декодированных операций, то есть из запасов процессора, если надо что-то повторно использовать.

И далее микрооперации собираются в очереди для переопределения порядка и выполнения. Ну и тут начинаются уже самые значительные отличия между intel и AMD. В AMD есть историческое деление на блоки целочисленных вычислений и вычислений с плавающей точкой, так же в AMD есть фиксировано расположенные исполнительные блоки, к которым есть постоянные связи от планировщиков. Здесь же находятся связи с кешем L1 данных, то есть тут вместе встречаются микрооперации с данными для операндов и в исполнительных блоках выполняются и затем записываются результаты.
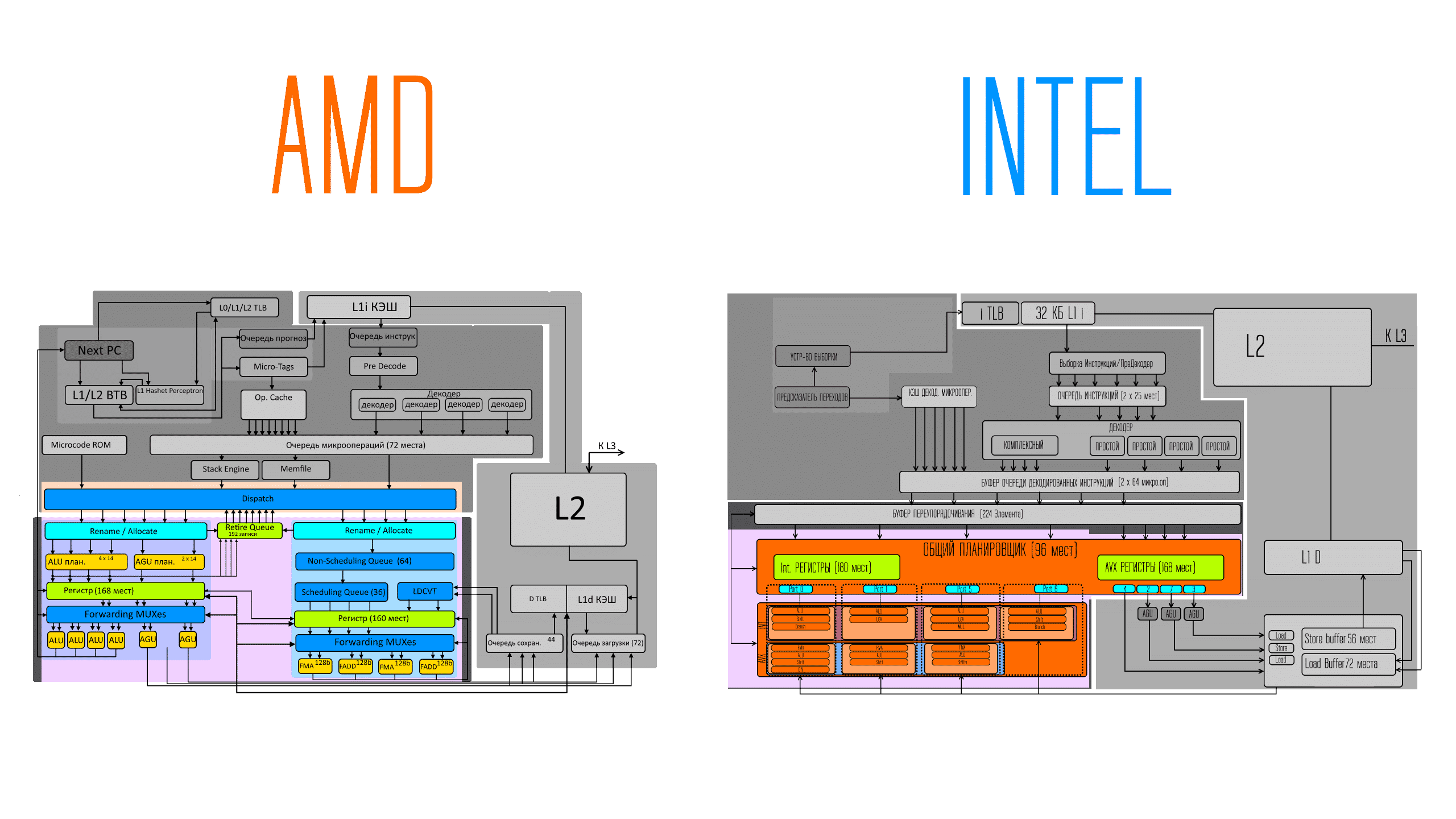
В intel нет жёсткой связи, такой, что есть строгий путь к каждому исполнительному блоку. Тут точно так же уже операции встречаются с операднами и происходит выполнение этих самых операций с последующей их записью, но в intel после планировщика идут порты (обозначены голубым) через которые доступны наборы исполнительных блоков. То есть в зависимости от самой задачи для каждого такта выбирается один из исполнительных блоков доступных через каждый порт, достигается это очередями и внеочередным выполнением, задача всего этого — наиболее плотно заполнить исполнительные блоки каждый такт. Самые ходовые исполнительные блоки дублируются в нескольких портах, то есть в зависимости от задач процессор сам может подстраиваться под то какие блоки ему нужны, а ограничение в производительности появляется из-за ограниченности количества портов, ну и затыками на любых этапах работы связанных с не получением данных своевременно.
В общем — это если коротко о разнице между intel и AMD в глобальном исполнении конвейеров, понятное дело, что даже схожие вещи реализованы у каждого по своему, но местами сама суть одинаковая, а местами — разная.
Архитектура intel Sunny Cove (Ice Lake)
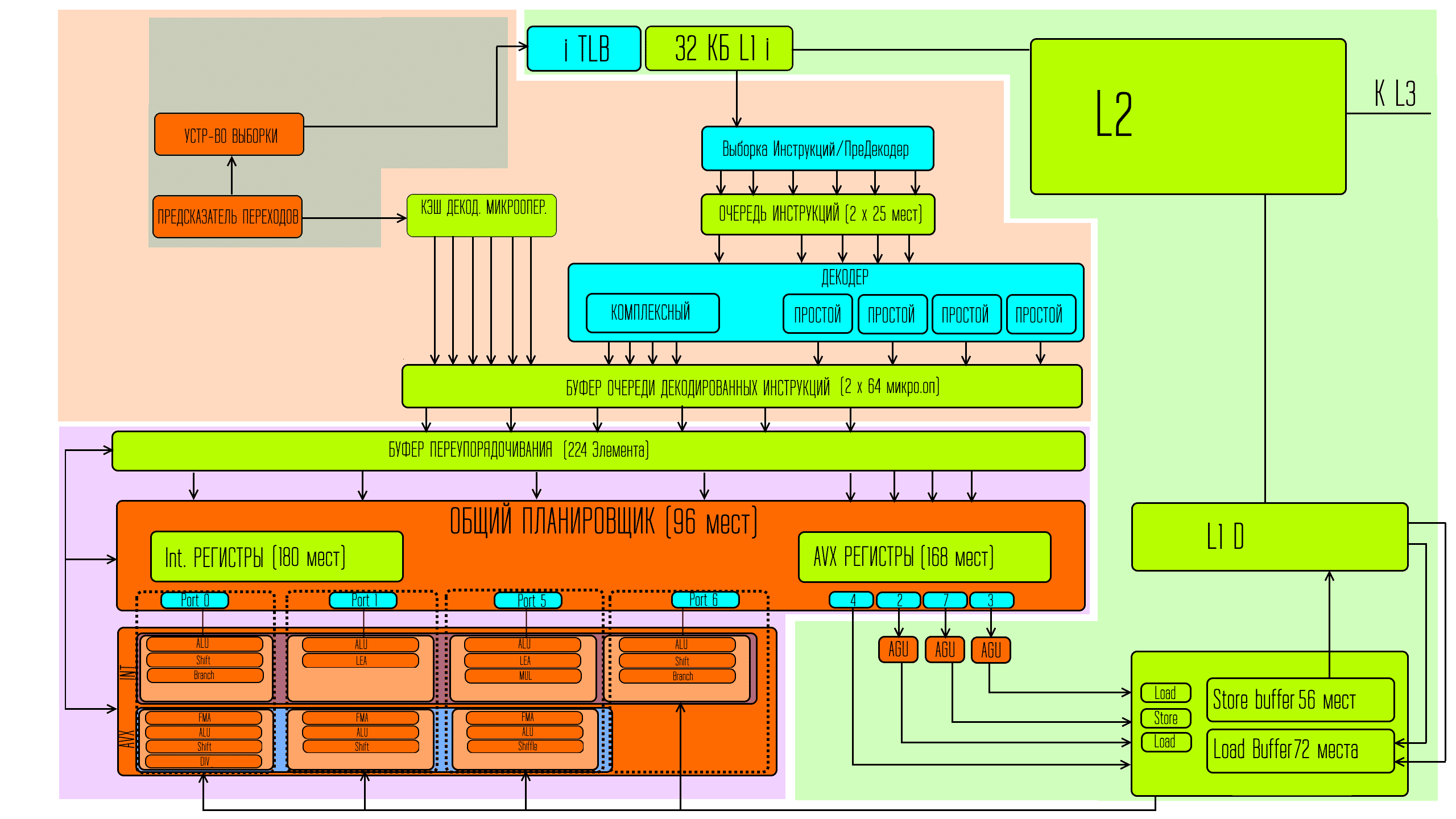
Рассмотрим основные этапы работы конвейера. Начнём с предсказаний ветвлений.

В этой области со Skylake изменения есть и связаны они с улучшением предсказаний, и уменьшением числа ошибок. Каких-то конкретных или даже абстрактных цифр улучшения для каких-то типичных сценариев работы не заявлено, заявлено что улучшена логика работы, увеличено количество анализируемых данных для предсказаний и, что это стало работать лучше. Это, в общем-то одна из самых важных для современных процессоров областей, и наверное, и самая сложная, поэтому как-то описать изменения понятным языком компаниям было бы сложно, поэтому нормальных понятных описаний и нет, в общем и целом просто заявлено, что стало лучше.
Возвращаясь к основной центральной ветви конвейера пройдём по декодеру.

В сравнении с архитектурой Skylake — в Ice Lake изменений в размерах буферов преддекодирования и в размере передаваемых страниц — нет. очередь инструкций так же осталась равной 25 элементам на поток, то есть 50 элементов на ядро.
В декодировании тоже кардинальных отличий нет. Есть 4 простых и один сложный декодер, который как и ранее может декодировать 1 инструкцию на не более чем 4 микрооперации. Также есть буфер отвечающий за временное сохранение уже декодированных микроопераций, из которого по необходимости так же могут запрашиваться микрооперации до шести за такт.
Этот буфер в Ice Lake увеличился с 1,5 тысяч до 2 тысяч записей (2048 записей).

От всех источников микрооперации поступают в специальный буфер очереди декодированных инструкций, который может хранить 64 микрооперации на поток, то есть 128 микроопераций на ядро. Из него микрооперации по 6 за такт поступают в блок внеочередного выполнения команд.
В нём есть буфер переупорядочивания. В Skylake этот буфер был на 224 элемента, в Ice Lake 352 элемента.

Из этого буфера микрооперации передаются планировщику. В Skylake передаётся не более 8 микроопераций за такт, в Ice Lake — не более 10. Планировщик располагает регистрами куда заносятся данные операндов для обычных и векторных команд. Эти регистры тоже должны были увеличиться в сравнении со Skylake’ом в Ice Lake. И они скорее всего увеличились, но их размеры не заявлены. И уже тут операции встречаются с операднами и как раз через ранее упомянутые порты — передаются к исполнительным блокам. В Skylake этих портов было 8, в Ice Lake их стало 10.

Но изменения тут не только в количестве. Начнём с того, что исполнительные блоки именно для вычислений, как и ранее, доступны только через 4 порта, которые intel нумерует как 0 1 5 и 6.
В них есть изменения как количественные так и качественные. В intel перераспределили некоторые блоки по другому между портами, и добавии ещё новых блоков. То есть теперь у процессора есть большая вариативность по использованию всех 4-х портов более плотно для самых различных комбинаций задач.

Кроме того часть векторных исполнительных блоков стали 512 битными и соответственно были введены новые 512 битные инструкции для того чтобы эти новые блоки задействовать именно как 512 битные. 512 битная инструкция позволяет впихнуть в себя до 64 простейших операций одинарной точности и до 32 операций двойной точности. И всё это может проталкиваться по конвейеру блоками, упрощая всю логистику.

Но именно с исполнительными блоками для вычислений осталась как и было ранее — 4 порта. А общее увеличение с 8 до 10 портов произошло для блоков, которые заняты работой с записью и чтением данных. С одного до двух увеличилось число портов для практически прямого соединения буферов после планировщика с буфером очередей для записи в кеш L1 данных. Второй новый порт используется для блока генерации адресов для записи данных.

То есть теперь два порта на прямую связь с буфером очереди на запись в память, два порта на AGU для загрузки и два порта на AGU записи. Кроме этого увеличились буферы очередей загрузки и записи для работы с L1 кешем данных. Для загрузки с 72 до 128 элементов, и для записи с 56 до 72 записей.
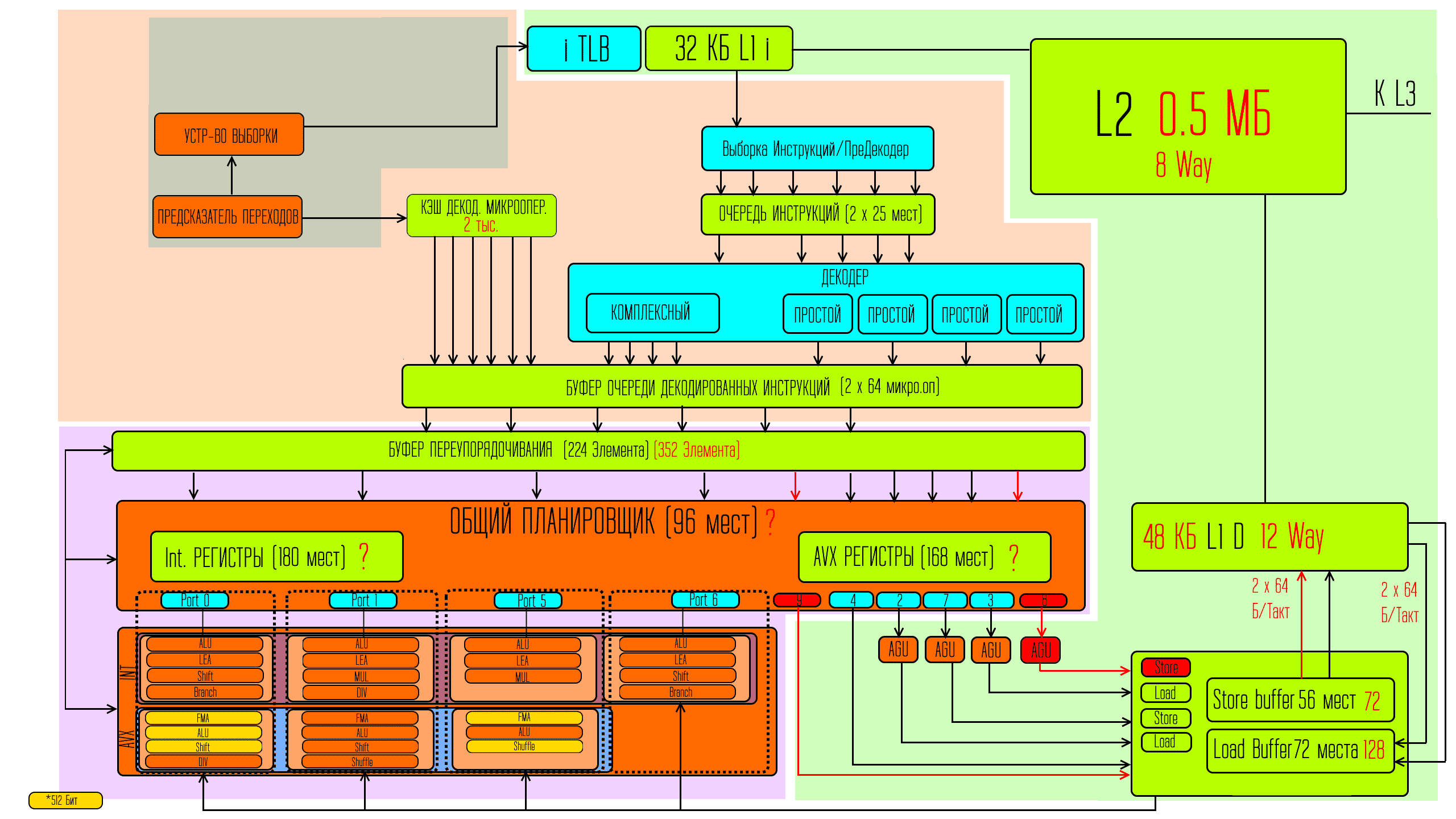
Кроме этого сильно выросли скорости соединения этих буферов с кешем L1 данных. на запись в кеш было 32 Байта за такт, а стало два канала по 64 байта за такт, то есть ширина канала выросла в 4 раза. Для загрузки данных было два по 32 байт за такт а стало два по 64 байта за такт, то есть ширина выросла в два раза. Сам кеш L1 данных вырос с 32 до 48 КБайт, ассоциативность изменилась с 8 до 12. Увеличился и кеш L2 с 256 байт на ядро до 512 байт. Изменилась и ассоциативность кеша L2 с 4 до 8.
И это основные изменения в новой микроархитектуре процессоров.
Выводы и перспективы будущих улучшений
Изменений довольно много. Вернее довольно много, если бы Ice Lake вышел два года назад как и планировалось, а не сейчас. В итоге так вышло, что Sunny Cove стала заложником долгого перехода на новый техпроцесс, так что intel как бы пропустят её, она будет только в Ice Lake, и уже в 2020 году в процессорах intel Rocket Lake эта архитектура заменится на willow cove. 2020 год — это был бы вполне нормальный срок для перехода на обновлённую архитектуру в сравнении с Sunny Cove которая должна была выйти в 2017 или 2018 году. Про новую архитектуру 2020 года известно пока не так много, тем не менее на сайте есть отдельный материал о том что сейчас известно об архитектуре и будущих процессорах. Но если коротко, то увеличится кеш L2 до 1,25 Мб на ядро, L3 до 3 Мб на ядро, добавятся ещё новые 512 битные инструкции.

Если говорить про внеядерную часть ещё появится новая графика на основе intel Xe до 96 блоков графики. Ходят слухи что будут процессоры даже с 2 ГБ HBM памяти но опционально для каких-то конкретных устройств. Ещё изменятся контроллеры PCI-e: процессоры получат PCI-e 4.0, так что не исключено, что в intel сразу подготовятся и к будущему переходу на DDR5. Эта подготовка может заключаться в увеличении ширины кольцевой шины, которую в прошлый раз расширили при переходе на память DDR4. Естественно с переходом на PCI-e 4.0 произойдёт и переход на шину DMI4, что позволит использовать более быстрые внешние устройства или большее их количество. Правда есть одно весомое НО. Rocket Lake будут опять только в качестве процессоров для ультрабуков, в версии с HBM памятью это может быть и попадёт в относительно настольный сегмент, в виде NACов.

Ещё есть слухи, что intel архитектуру willow cove перенесёт с 10+ нанометров на 14 %сколько-то плюсов% нанометров, и в таком виде willow cove появится в настольных компьютерах в 2021 году.
Касаемо рассмотренной архитектуры Sunny Cove — скорее всего обещанные +18% к выполнению инструкций за такт тут и есть. Хорошо ли это для одного перехода между поколениями? Безусловно. Хорошо ли это учитывая, что эта разница за почти 5 лет? Уже не так однозначно хорошо.
 Подписаться на канал
Подписаться на канал
