Не так давно на сайте был материал в котором мы смотрели на то как процессор сам ядрами отрисовывает игры. При этом процессор потреблял огромное количество энергии, выдавая почти ничего. В тоже время даже встроенная графика в этот процессор потребляя полтора десятка ватт смогла бы выдать производительности раз в пять больше.
Исходя из этого возникает вопрос — «почему так происходит и почему есть и процессор и видеокарта?». Ведь по данному материалу может показаться, что видеокарта не слабо так мощнее процессора. И встаёт вопрос — зачем тогда нужен процессор.
Поэтому предлагаю разобраться в чём причина наличия обоих вычислителей в компьютере и ещё ещё рассмотрим историю одного проекта intel, который как раз был направлен на сочетание всех положительных сторон этих вычислителей и уменьшении отрицательных.
С устройством ядер процессора я уже вас знакомил в некоторых прошлых материалах, есть статья и про архитектуру современных Intel процессоров и про AMD, но основные моменты напомню ещё раз.
Между Intel и AMD местами есть довольно большая разница, но если разделить работу на 4-5 этапов, то есть максимально обобщить суть работы — то в целом — суть у них одна и та же. И для удобства остановимся на схеме из статьи про Intel.

Условно можно сказать что есть некоторая центральная часть — это исполнительные блоки, в которых и происходит вычисление. И к этой основной части должно прийти две важные вещи. Первая это — «что делать», а вторая — «с чем делать». Чтобы это всё было поставлено в исполнительные блоки точно вовремя есть очереди и регистры в которых эти очереди реализованы. И все эти сложности направлены на то, чтобы каждый такт процессора подобрать такие комбинации различных задач чтобы занять наибольшее количество исполнительных блоков.
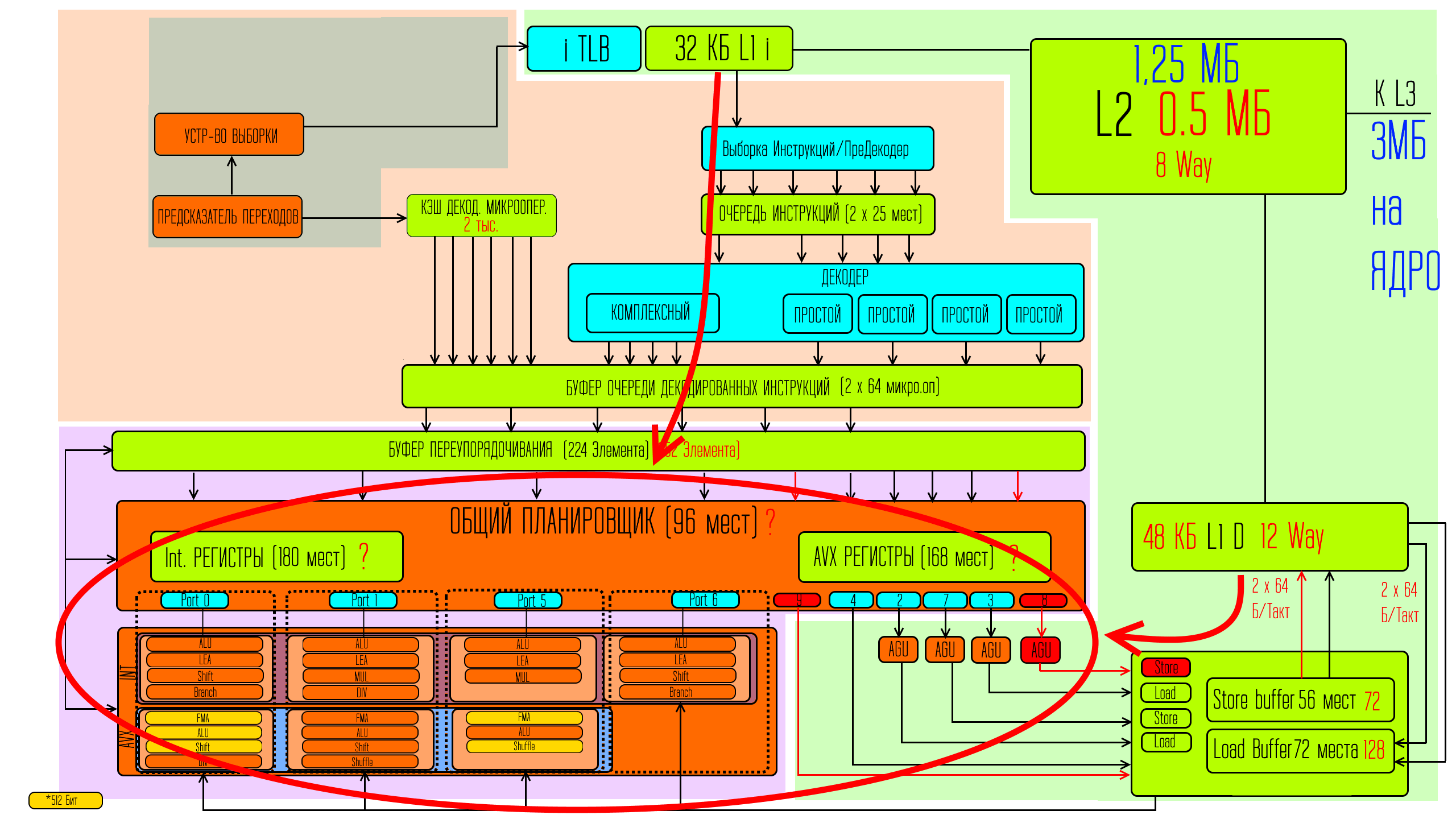
То есть не так сложно выполнить вычисления, сложно сделать так, чтобы различные задачи можно было выполнить без лишних простоев, связанных с постоянным изменением задачи. Именно поэтому растут и объёмы кеша, да и размеры регистров очередей, чтобы как можно больше поблизости с ядрами хранить «что делать» и «с чем делать», и также хранить что было сделано ранее, чтобы временами на основе этого делать что-то похожее в будущем, затрачивая меньше ресурсов, или делать что-то, когда новых ресурсов ещё нет, проверяя правильность выполнения работы уже постфактум, когда ресурсы появятся в доступе.
Дополнительная большая проблема заключается в том, что современные процессоры наследуют совместимость с довольно старыми решениями. Архитектуре x86 уже не мало лет и в процессе её развития в определенный момент она так сильно усложнилась, что сделать адекватные по составу, и требованиям к количеству транзисторов исполнительные блоки, стало сложно. И с переходом на Pentium III классическая CISC архитектура предполагающая высокую гибкость по возможным командам стала уже мешать дальнейшему развитию процессоров. И Intel пошли на смелый шаг — сделать внутри процессора — аппаратно-программный комплекс по переводу в режиме реального времени разнообразных CISC команд в более узкие по возможностям команды, но с которыми было бы легче работать и выстраивать из них очереди и выполнять. AMD пошли по тому же пути.
То есть возникла матрёшка имеющая внешнюю оболочку, внутри которой уже настоящее ядро.

Но все внешние общения процессора производятся так, как буд-то внутренней части нет. И это создаёт немало сложностей из-за которых внутренние адресации процессора не совпадают с внешними, возникает и ещё куча проблем связанных с тем, что внутри ядра происходит очень сильное переопределение порядка как выполнения самих операций изначальных, так и частей уже разбитых на микрооперации внутренних решаемых ядром задач. Но на выходе процессор должен собрать всю очередь обратно так как буд-то ничего не перемешивалось.
И все эти сложности направлены на то чтобы обеспечить индивидуальный подход к каждой задачи и получить максимальную производительность.
Как вы понимаете — при отрисовки игр — мы имеем дело с кучей однотипных задач. Но процессор по другому решать задачи не умеет, и с индивидуальным подходом массовые задачи решать сложно. Вернее процессоры массово выполнять что-то умеют, но не всегда. Существуют специальные инструкции, которые собирают ряд однотипных задач над неким набором данных для совместного выполнения.

Например AVX инструкции. Благодаря этому компонованию — внешний слой матрёшки надо проходить не для каждого действия отдельно — а блоком целиком. Что уже сильно ускоряет весь процесс по решению задачи, кроме того — процессор знает, что некоторые используемые данные и операции будут применяться в ближайшее время по несколько раз, что упрощает очереди и меньше надо туда-сюда между регистрами лишний раз перебрасывать информацию. Но всё равно — производительность будет ограничиваться числом портов на исполнительные блоки у Intel и числом исполнительных блоков у AMD в самом радужном раскладе, который на практике недостижим.
В видеокартах же всё происходит совсем иначе.
Во первых — современный вариант видеокарт, в которых появились вычислительные блоки, общего назначения — появился гораздо позже архитектуры x86, и сложность в выполнении широкого круга разных операций уже была понятна, так что делать CISC ядра никто и не думал. И никакие обратные совместимости не требовали делать какие-то мартёшочные костыли. Поэтому процессоры в видеокартах умеют работать с малым числом инструкций, но зато работать с ними они могут непосредственно не переделывая, и от этого — эффективно.
Из этого сразу можно сделать вывод, что заменить процессор для привычных нам сред работы видеокарты не могут просто в силу архитектурных ограничений, они просто не могут работать с тем разнообразием задач и команд без предварительной трансляции их в понятный для видеокарт вид.
Ну и собственно процесс работы с видеокартами вообще бывает разный. И как раз чтобы работа с видеокартами была максимально без посредников существуют API на которых работают игры и прочие средства для разработчиков, которые позволяют работать с аппаратными ресурсами видеокарт непосредственно для какого-то прикладного софта.
Но это только половина дела. Особенность задач для видеокарт заключается в том, что им надо повторить одни и те же действия для кучи данных. То есть задача совершенно иная, в отличие от центрального процессора, который должен максимально оперативно подстраиваться под разные задачи.
Соответственно и архитектурные особенности видеокарт были созданы так, чтобы именно такие задачи и решать.
В процессорах планировщик, который ведает всеми очередями и решает когда и кто из них выйдет — занимается очень сложной задачей, потому что всё разное и надо это всё разное как-то скомпоновать в разные исполнительные блоки.
В видеокартах тоже есть планировщики, но задачи у них проще. Надо взять кучу чего-то однотипного и раскидать это по всему что есть. Именно поэтому в процессорах планировщик ведает малым числом исполнительных устройств. В видеокартах — каждый планировщик отвечает за целые большие кластеры исполнительных устройств, которые называют ядрами видеокарт или потоковыми процессорами видеокарт.

И то, количество задач, которое центральному процессору потребовалось бы распределять на доступные ему вычислительные средства на несколько тактов работы, в видеокартах планировщики делают за один такт. То есть передают команды целой армии исполнителей, которые тоже максимально упрощены под узкий круг решаемых задач.
При этом для видеокарт однотипных задач так много, что там решая целые кучи вычислений — всё равно эти задачи разбиваются на много тактов, смены задач происходят редко, так что и хранить что-то не так важно, и удельный объём кешей на каждый исполнительный блок на порядки меньше, чем у центральных процессоров. В общем — вся обвязка и всё обеспечение инструкциями и данными для видеокарт сильно проще, чем у центральных процессоров, и занимает куда меньше места. А значит — на равную площадь можно запихать очень много вычислительных блоков.
Однако стоит отметить, что архитектуры видеокарт для универсальных вычислений появились тоже уже довольно давно. Так что концепция — объединения вычислительных потоков под простые планировщики, которые почти ничего не должны уметь — устаревает.
Вычислительный потенциал карт не даёт покоя никому, ни игроделам, ни другим программистам работающим над каким-то прикладным софтом. Поэтому всё более сложные работы начинают передавать для вычислений видеокартами. Естественно это отражается и в эволюции API и SDK для работы с ресурсами видеокарт, но так же это требует и модернизации самой концепции видеокарт.
И карты от AMD и от Nvidia, с горем пополам, если сравнивать с центральными процессорами, уже могут выдавать разные задачи на разные блоки видеокарты, а не так чтобы у всех одно и тоже, а если нужно что-то другое, то надо ждать следующих тактов.
То есть видеокарты идут в сторону усложнения, что, скорее всего лишит их по меньшей мере энергоэффективности. Будет падать и удельная площадь кристалла занятого ядрами (на схеме выше вы можете увидеть, что на Тюринге уже стоит планировщик на каждые 16 ядер, а не 32, как было ранее), то есть будет больше транзисторного бюджета уходить на обвязку ядер и оставаться меньше места для того чтобы разместить больше ядер.
Итого подведем итоги и ответим на вопрос о том: почему есть и процессор и видекарта. Ответ — вполне прост. Видеокарта хороша тогда, когда есть очень много однотипных задач, она энергоэффективна, она имеет высокую вычислительную производительность, но видеокарты не могут эффективно работать в условиях постоянного изменения задач и лишены тех костылей, идущих из прошлого, для обеспечения совместимости со стандартами, которые стали неотъемлемыми для персональных компьютеров.
Центральный процессор может адаптироваться к постоянно меняющимся задачам, имеет много удельного кеша на ядро, и может выполнять более широкий спектр инструкций, но имеет очень большую обвязку для ядер, так что много ядер делать дорого, и из-за костылей имеет низкую энергоэффективность, которая также ограничивает возможности процессоров.
Но и тот и другой тип вычислителей сейчас идут друг к другу на встречу. Центральные процессоры уже могут в одну 512 битную инструкцию запихивать больше десятка операций, выполняя их максимально приближенно к единому блоку, видеокарты, в свою очередь, учатся выполнять одновременно разнородные задачи без значительных простоев потоковых процессоров.
Можно предположить, что должно появиться такое решение, которое будет гибридом этих двух вариантов. То есть будет гибким при выполнении разнородных задач, но при этом иметь много потоков и хорошо справляться с управлением этими потоками.
И попытка сделать такое устройство уже была сделана, но, к счастью или сожалению — устройство оказалось не столь удачным как хотелось бы.
Intel с середины 00-х до середины 10-х годов уже почти выпустили новый для себя и вообще для всего мира продукт Larrabee.

Это не должно было заменить центральный процессор, но и не должно было стать и просто видеокартой. Суть в том что Intel хотели объединить порядка 50 слабых процессоров, в единый вычислительный кластер.
Оно должно было сохранить x86 совместимую архитектуру, собственные планировщики и много кеша, но при этом ядра не умели бы переупорядочивать выполнение микроопераций и просто должны были рассчитывать на большой кеш для уменьшения простоев в работе. Но зато они бы были намного меньше по площади.

Кроме того в ядра должны были быть добавлены специальные вычислительные блоки для работы с текстурами. То есть оно могло бы работать и как видеокарта. Ещё в этих гибридных процессорах должна была быть очень широкая шина связи ядер, а аналог HT выдавать не 2 потока на ядро, а 4, что с одной стороны увеличило бы сумятицу, без переопределений очередей и потребовало бы больший кеш, с другой стороны — в части задач могло бы увеличить пиковую производительность на такт за счёт более плотного задействования исполнительных блоков.

В конечном итоге данный проект как нечто напоминающее видеокарту не появились, часть всяких лишних для вычислителя возможностей было вырезано и всё это превратилось в процессоры Xeon Phi, а появившиеся впервые предпосылки к 512 битным инструкциям, которые могут вместить в себя до 16 операций с плавающей точкой уже дошли и до обычной архитектуры intel Тигер лейк.

В общим — отдельные фрагменты этих гибридов оказались жизнеспособными и успешно внедряются в различные решения от intel.
Но скорее всего соединяя процессор и видекоарту вместе, достоинства обоих методов видно будет не так хорошо, как суммирующиеся недостатки обоих методов.
Именно поэтому существует по отдельности процессор и видеокарта и друг друга они заменить, по крайней мере сейчас — не могут.
 Подписаться на канал
Подписаться на канал

