Содержание
Начнём же мы с глобальных изменений, то есть не на уровне ядра, а на уровне всего процессора.
Компоновка и чиплетная архитектура
Во первых кардинально изменилась компоновка — процессор перестал быть монолитным, а поделённым на несколько чиплетов.

Если коротко, то AMD вырезали из старого процессора часть с ядрами, добавили к ней контроллер для связей между чиплетами и сделали из этого отдельный кристалл на 7нм, заказывая эти кристаллы в TSMC.

Внеядерные части собрали в кучу и сделали из этого ещё один кристалл. Это, естественно, приносит как плюсы, так и минусы.

Плюсы — это, безусловно, стоимость производства. Сейчас одни и те же чиплеты с ядрами применяются, и в Ryzen, и в Threadripper, и в EPYC процессорах.

То есть TSMC просто штампует маленькие кристаллы на 7 нм и всё. Маленькие кристаллы — это экономически очень выгодно. Себестоимость производства рассчитывать надо не на один процессор, а на целую кремниевую пластину, да и если вы посмотрите на отчёты компаний занимающихся литографией в кремнии, они указывают и продукцию и производительность именно в пластинах, а не в процессорах, например.

При малой площади кристаллов — из одной пластины получается больше процессоров, а значит при равной стоимости изготовления пластины — каждый отдельный процессор — дешевле в производстве. Кроме этого — в процессе производства неизбежен брак, и если кристаллы крупные, то одинаковое количество дефектов приведёт к выходу из строя кристаллов существенно большей площади. Именно технологическая оптимизация была главной особенностью и, скорее всего, главной целью которую AMD ставили перед собой для новой архитектуры. Но, естественно, такой подход приносит и свои недостатки..
Объединить кристаллы друг с другом можно двумя способами, ну вернее 2,5 способами, если говорить ещё про intel и кремниевые EMIB мосты.

У AMD же выбора было два.
Первый — это поставить чиплеты на общую кремниевую подложку и через подложку соединить кристаллы так, как будто бы это и вовсе один кристалл никак себя не ограничивая, как это происходит, например, при подключении HBM памяти. Такой метод бы позволил не получить значительного роста задержек между чиплетами и в целом — можно было бы оставить ядра Zen+ практически неизменными. Но это бы потребовало делать к маленьким кристаллам ядер и кристаллу с контроллерами ещё общий большой кристалл подложку.

Он был бы не очень дорогой, так как требовал бы меньшего числа технологических операций, чем для ядер и контроллеров и такую подложку можно было бы делать на старом оборудовании из менее чистых материалов и это бы нормально работало. Но это всё равно дополнительные затраты, и кроме этого пришлось бы скорее всего попрощаться с сокетом AM4 в пользу более крупного решения, не исключено, что пришлось бы даже опять менять расположение отверстий под кулер.
Второй путь для AMD был — разделить кристаллы, соединив их через текстолит.

Это решение, с точки зрения производительности — плохое. И в целом — отбрасывало бы процессоры примерно к началу 2010 годов по производительности, если бы не тот факт, что 7 нм дали AMD возможность сильно увеличить число транзисторов в чиплетах и пустить эти транзисторы на то, чтобы сделать сами ядра и чиплеты с ядрами более независимыми от всего внешнего мира.
Изменения кэша и внутренних шин
Вдвое была увеличена ширина infinity fabric и это частично решило вопрос обменов между компонентами, но только в части пропускной способности, а не задержек. Но главное изменение, которое было введено для парирования снижения производительности — это двукратное увеличение кэш памяти L3.

Процессорам гораздо реже надо обращаться к чему-то вне кэша. При этом как вне и своей части кэш памяти, так и к кэшу в соседнем блоке или кешу в соседнем чиплете с ядрами. Это главное вынужденное изменение, которое, как практика показывает, с лихвой покрыло недостатки связанные с отделением контроллера памяти от ядер.

Помимо этого AMD ещё выделили отдельный делитель для частоты шин infinity fabric, которая работает синхронно с контроллером памяти, что позволило добиться большего разгона памяти, правда с оговорками. На частоте выше 3800 МГц (официально заявленной 3733) по памяти включается половинный делитель для infinity fabric , который рушит весь потенциальный прирост в уменьшении задержек с дальнейшего разгона памяти.

С другой стороны этот делитель показал то, насколько хорош в Ryzen контроллер памяти, не в задержках правда, а в частоте. Сейчас рекорды разгона памяти DDR4 за Ryzen.

Но изменением компоновки и увеличением кеша различия архитектур не ограничиваются. Есть изменения и в самой микроархитектуре ядер, то есть AMD не просто взяли блоки ядер, добавили кеша L3 и этим получили новый процессор.
Изменения микроархитектуры в Zen2
Изменения произошли эволюционные, то есть не кардинальные, то есть микроархитектура осталась той же, что и была, но местами улучшенная.
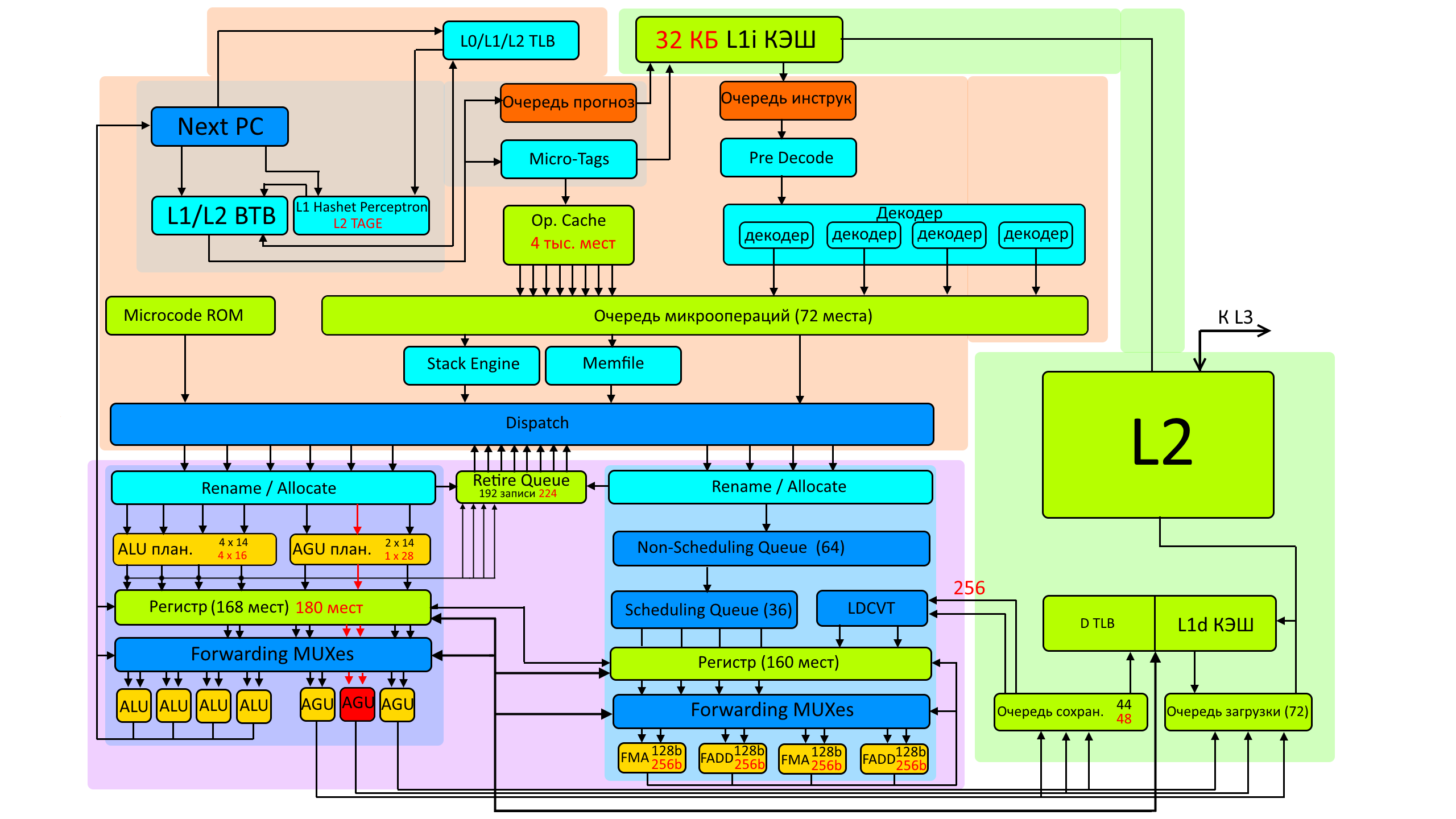
Ну и начнём мы с визуализации конвеейра ядра для архитектуры Zen+, без него сложно будет понять что и где изменилось.

Весь конвейер можно разделить по смысловой части на несколько частей, на изображении — это полупрозрачный цветной фон, начало конвейера сверху, а завершение снизу, сбоку (салатовым) области для записи результатов и идущие обратные связи от конца к началу, то есть сверху у нас поступают задачи, а снизу получаются результаты.

Первая область — это зона для декодирования инструкций, а так же тут находится предсказатель ветвлений. Для AMD далее происходит разделение конвейера на две практически независимые ветви, это блоки целочисленных операций и блоки операций с плавающей точкой, которые включают в себя и регистры для временного хранения информации и исполнительные блоки которые отвечают за выполнение задачи и за работу с памятью.
Общий смысл работы следующий:
Новые инструкции заходят сверху, декодируются в понятные процессору микрооперации и затем в зависимости от типа переводятся либо в сторону ALU, либо в сторону FPU, выполняются, и записываются. Всё остальное — это тонкости связанные с повторным использованием данных, перемещению этих данных, с накоплением их в очередях и записи их после выполнения.
А теоретическая производительность описывается в целом двумя параметрами — первый это сколько процессор может декодировать инструкций за такт, то есть шириной входа, и второй параметр — это сколько процессор может выполнить инструкций за такт, то есть шириной выхода.

Кроме теоретической производительности есть ещё вопрос и практической производительности, о которой поговорим чуть позже.
Но к слову, изменилась и теоретическая и практическая производительность.
С точки зрения ширины входа — изменений у Zen2 в сравнении с Zen+ нет. Это те же 4 инструкции на такт для декодера, плюс до 8 инструкций которые ранее были перемещены в очередь микроопераций и хранились в кеше микроопераций.

К слову в некоторых источниках говорится о том, что из кеша микроопераций и из декодера может в сумме выходить 8 микроопераций за такт, но на слайдах самой AMD это 8 микроопераций из кеша и 4 микрооперации вновь декодированных, то есть в сумме 12. Будем считать, что слайды AMD более достоверны.
Далее специальный передатчик может за такт передать до 6 микроопераций за такт в сторону целочисленных блоков, и до 4-х микроопераций в сторону блоков вычислений с плавающей точкой.

В самих половинках так же ещё есть свои небольшие регистры для хранения текущих данных и далее это всё отправляется на исполнительные блоки (жёлтые снизу схем) и вот тут как раз начинаются первые изменения с точки зрения теоретической производительности Zen2, всё что было ранее в рассказе для теоретической производительности Zen+ и Zen2 одинаковое. А вот с исполнительными блоками разница есть. AMD добавили один исполнительный блок AGU для генерации адресов, который принадлежит половине в которой расположена исполнитеьные блоки для целочисленных вычислений.

То есть в этой части стало возможно выполнять не 6 инструкций за такт, а 7 инструкций за такт. Изменился планировщик для блоков генерации адресов, ранее их было два работающих с 14 элементами каждый, теперь он стал один но удвоенный, чуть шире, с 14 до 16 элементов стали планировщики и для ALU, и для хранения данных увеличен регистр который ранее мог хранить 168 записей, а в Zen2 его увеличили до 180 записей. Несколько возросла и очередь хранилища записей после AGU с 44 до 48 мест. В целом — про изменения в регистрах будет речь когда рассказ дойдёт до практической разницы, а не в теоретической, но в данном месте ширина конвейера увеличилась на 16%, за счёт ещё одного исполнительного блока, а величины регистров которые обжуливают эти конвейеры на 7%. Скорее всего AMD посчитали, что им нужны именно эти 7% увеличения регистров для нового блока генерации адресов.
А вот с блоками в зоне FPU изменения произошли более значимые. По количеству и составу изменений нет — это два блока для сложения и два для умножения. Но теперь они стали 256 битными. То есть вдвое шире, чем те, что были в Zen+. В Zen+ 256 битное сложение занимало сразу оба блока сложения, и 256 битное умножение занимало так же оба блока умножения, а так же передача этих инструкций занимала два такта. Сейчас же, в Zen2 весь тракт передачи и выполнения 256 битных инструкций — 256 битный, то есть передача и выполнение происходят по одному такту и используется по одному соответствующему исполнительному блоку.

В теории — всё понятно. Прирост выполнения операций за такт максимум до 16% в операциях кроме AVX 256 за счёт увеличения числа исполнительных блоков, и 100% прироста в AVX 256 за счёт увеличения ширины FPU.
Примерно такие цифры сами AMD и заявлили.

Сложнее дела обстоят с практикой. На деле исполнительные блоки целиком задействуются не каждый такт, то есть для части блоков не подбирается то что они должны выполнить, более того даже можно увидеть, что в сторону ALU и AGU поступает 6 микроопераций за такт, а выполнить они могут 7. Цифры явно не сходятся.

И сверху можно увидеть, что в теории процессор может передать целых 12 микроопераций в сторону исполнительных блоков, а передаёт 6+4 максимум, то есть 10. Иными словами — всегда все блоки не задействуются и это — нормально. Если бы не SMT тут в райзенах или HT у intel — то блоки бы задействовались бы ещё менее плотно.
Тут то и возникают все отличия между теоретической и реальной производительностью. Допустим из-за отделения контроллеров памяти появился ещё один посредник в виде инфинити фабрик, увеличились задержки обращения в память, из-за которых чаще могут возникать простои процессора от того что он не может получить данные. Для парирования этого практического снижения производительности был увеличен кэш L3, процессор так же долго будет ждать данных, но из-за большего кеша — будет делать это реже.

Как показывает практика с играми на Zen2, скорее всего общее время простоя благодаря увеличению кеша даже с большими задержками — уменьшилось. То что, с увеличением кэша стало меньше обращений по инфинити фабрикам — это тоже хорошо.
Но работа с кешем L3 — это внеядерная часть.
Но и в самом ядре разница тоже есть.
Во первых — процессор не всегда использует только-только декодированные микрооперации, и зачастую это связано с тем, что процессор ещё не знает с чем выполнять только что декодированные инструкции. Допустим процессору надо к «А» прибавить единицу, а потом сравнить больше ли» А» чем 0.
И эти инструкции идут на процессор подряд, он их декодирует, но конвейер длинный, пока «А=А+1» дойдёт от входа до выхода и процессор получит новую «А» для сравнения пройдёт больше 10 тактов. Процессор не может просто ждать 10 тактов. Поэтому по своей готовности процессор оценивает каким будет результат для ветвления, исходя из предыдущих операций и делает предположение и не дожидаясь того как одна операция пройдёт весь конвейер выполняет следующие. Эти механизмы забегания вперёд — довольно сложны и во многом они определяют реальную производительность современных процессоров. То есть чем они лучше работают — тем выше реальная эффективность. В AMD для Zen2 усовершенствовали эти механизмы предположений, ввели и более сложную и точную логику, а так же выделили больше места под хранение адресов записей, которые процессор может анализировать для принятия решений. В итоге эти изменения по данным AMD позволили ошибаться процессору при предположениях на 30% реже.

Ну и надо понимать, что это не значит, что процессор стал на 30% лучше. Допустим раньше процессор ошибался в 15% предсказаний, а сейчас стал ошибаться на 30% реже — в 10% предсказаний, то есть разница будет 5%. На деле процент ошибок от общего числа предсказаний AMD не рассказывает так что реальный прирост из имеющихся цифр не получить. Но в любом случае стало лучше чем было раньше.
Помимо этого AMD вдвое увеличили хранилище для уже декодированных микроопераций, с 2 тысяч, до 4-х тысяч мест. То есть запасы процессор может хранить чуть дольше и запасов этих намного больше.
Но увеличение этого буфера до 4-х тысяч мест было сопровождено уменьшением буфера для ещё не декодированных команд (кеш L1i уменьшился до 32 КБ). В общем — тут вопрос практической отработки архитектуры. В AMD посмотрели на реальную работу на практике и перераспределили ресурсы так чтобы они работали более эффективно.
Ну и на этом про саму архитектуру ядер — всё. Остались только контроллеры вынесенные в отдельный чиплет.
Помимо переезда в отдельный чиплет изменения коснулись и самих контроллеров, в частности контроллера PCI-e. Который «вырос» с 3-ей версии до 4-ой. Учитывая ещё и удвоение ширины инфинити фабрик можно сделать вывод о том, что внутренние части процессора к большим объёмам данных от внешних устройств тоже были подготовлены.

Скорее всего были обновлены и некоторые другие контроллеры. По меньшей мере выделение делителя для IF скорее всего потребовало каких-то значимых изменений и в контроллере памяти и в контроллерах инфинити фабрик, но подробностей об этих изменениях к сожалению нет.
Выводы
В совокупности — несмотря на огромные опасения в части разделения на чиплеты AMD, как показала практика, смогли за счёт грубой силы транзисторного бюджета нивелировать негативное влияние этих изменений. Процессоры получились хороши и в однопоточной нагрузке и в многопоточной. Есть отдельные задачи в которых intel с кольцевой шиной сильно выигрывают (не беря в расчёт цены процессоров), но уже не так сильно как раньше за счёт увеличения кеша в ядерных модулях Zen2. И если говорить про процессоры на сокете LGA2066 с шиной Mesh, то и эти процессоры в этих же задачах уступают обычным кольцевым процессорам intel.

То есть не только AMD, но и самой intel много ядер сделать так же эффективно как и мало — не получается.
 Подписаться на канал
Подписаться на канал


К сожалению, для задач, где больше 4ех потоков и требуется быстрая синхронизация между потоками(например игры) Увеличение объема L3 никак не повлияет на производительность, синхронизация будет медленная между отдельными чиплетами.
Такая архитектура очень хороша для серверов, для виртуализации.
Увеличение L3 будет влиять на производительность, так как будет меньше кэш промахов, ALU будут лучше загружены соответственно общая производительность возрастет. И вообще вероятно пока идет запрос к L3 на чтение, то могут исполняться другие команды независимые по данным от данного запроса
Так же непонятно, с чего это кристалл подложка лучше чем текстолит подложка. Это никак не влияет на общую архитектуру кэша и никак не влияет на задержки.