Содержание
Как многие знают — видеокарты можно разгонять. От этого у них увеличивается производительность. Но остаётся вопрос — можно ли разогнать RT и тензорные ядра? То есть разгоняются ли они вместе с CUDA ядрами.
Для ответа на этот вопрос я решил обратиться к документации Nvidia об архитектуре Тьюрингов. Но, к сожалению, нигде прямо или косвенно не указано, что RT ядра работают на частоте CUDA ядер. Наиболее близкое к этому — это раздел с описанием SM модулей, в которые входят CUDA ядра, тензорные ядра и RT ядра.

Опять же прямо этого не сказано, но судя по всему задачи на тензорные ядра распределяют те же планировщики, что и на CUDA ядра по два ядра на каждый планировщик или в сумме восемь тензорных ядер на SM модуль. Есть основания полагать, что работают они синхронно, либо с делителями, но всё равно на зависимых частотах. Про то что RT ядра как-то завязаны на какие-то конкретные планировщики в SM модулях ничего не написано. Более того и на схемах SM модулей RT ядра находятся отдельно от остальных блоков. Таким образом согласно документации нет причин считать, что RT ядра могут быть завязаны на частоты CUDA ядер.
Однако нет и оснований полагать, что RT ядра не завязаны на частоты CUDA ядер.
Что ж. Проблема понятна. Теперь надо по поведению системы и бенчмаркам понять что с чем связано, а что с чем не связано.
Анализ работы видеокарты при использовании тензорных и RT ядер.
Основная проблема в анализе заключается в том, что нет отдельных возможностей «просмотра» частот тензорных и RT ядер (возможно потому что они работают на частоте CUDA ядер).
Для начала зайдем в программу для визуализации трассировкой лучей SOLIDWORKS Visualize.
Сбоку включены графики от MSI Afterburner. При разворачивании окна с отрисовкой видеокарта переходит в частоты 3D режима. Так же и по энергопотреблению видно, что видеокарта чем-то занята. Так же чтобы вы понимали, что отрисовывает именно видеокарта, а не процессор я вывел и график загрузки процессора.
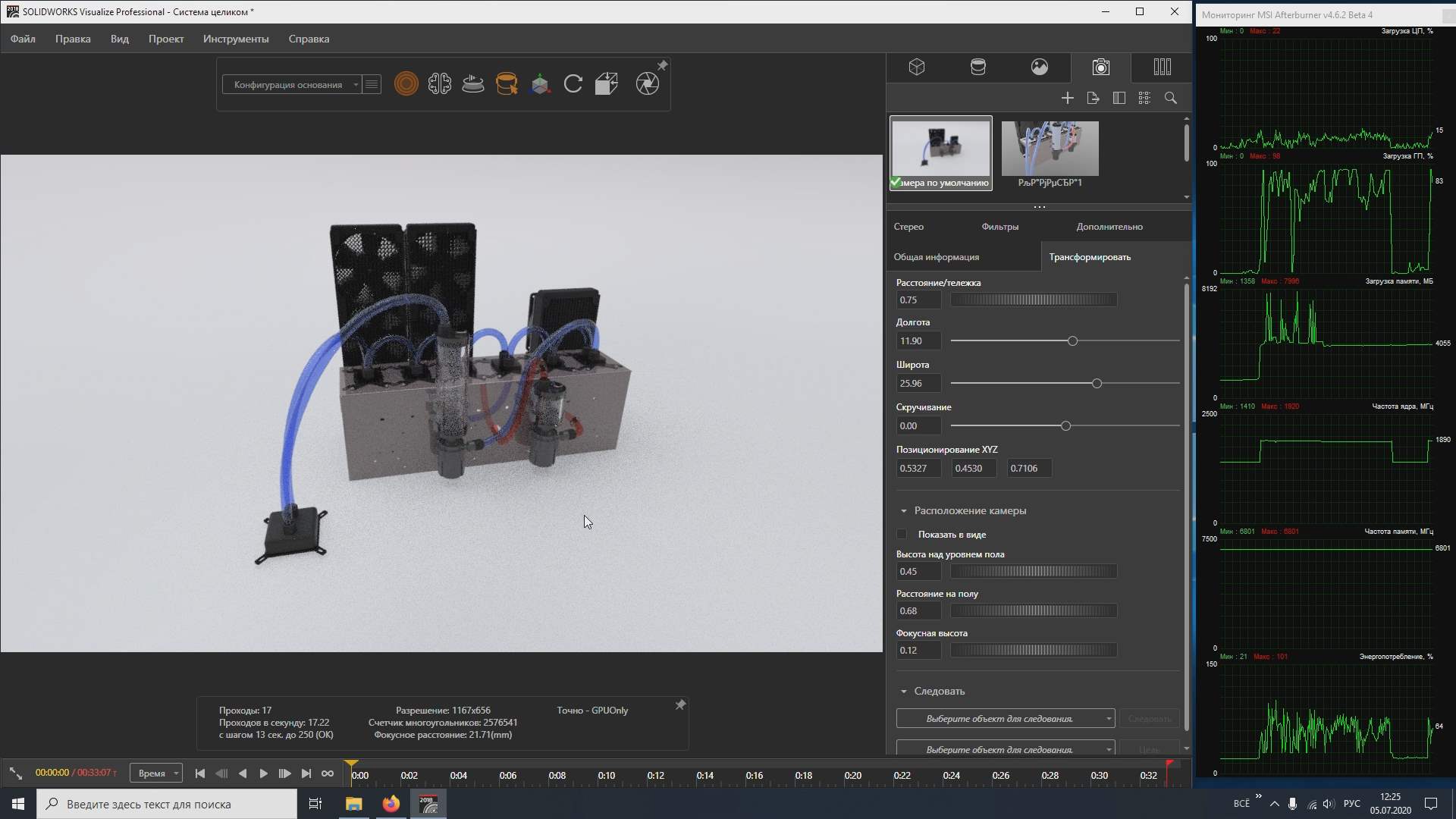
Данное поведение уже может намекать на то, что всё же RT ядра связаны по частоте с CUDA. Но всё же стоит учитывать, что в этой отрисовки под трассировкой лучей может быть подложка из обычной растеризации, однако при включении режима отрисовки без трассировки лучей после завершения движения камеры видеокарта переходит в 2D режим со сниженной частотой, и только при движении переходит в 3D режим.

Иными словами — переход на высокую частоту нужен именно для трассировки лучей.
Теперь рассмотрим поведение видеокарты при работе тензорных ядер.
Из всего что их задействует я нашёл опять же только SOLIDWORKS Visualize, который ими делает шумоподавление для того чтобы можно было уменьшать шум при малой плотности лучей, но у меня он не включает шумоподавление при финальной отрисовке, (возможно эта функция залочена только для видеокарт серии quadro), а вне финальной отрисовки производительность замерять сложно, а так же ещё остаётся бенчмарк с применением DLSS в пакете бенчмарков 3D Mark из которого мы косвенно получим данные о разгоне тензорных ядер.
Визуалайз при предварительной отрисовки делает шумоподавление после 9 прохода.
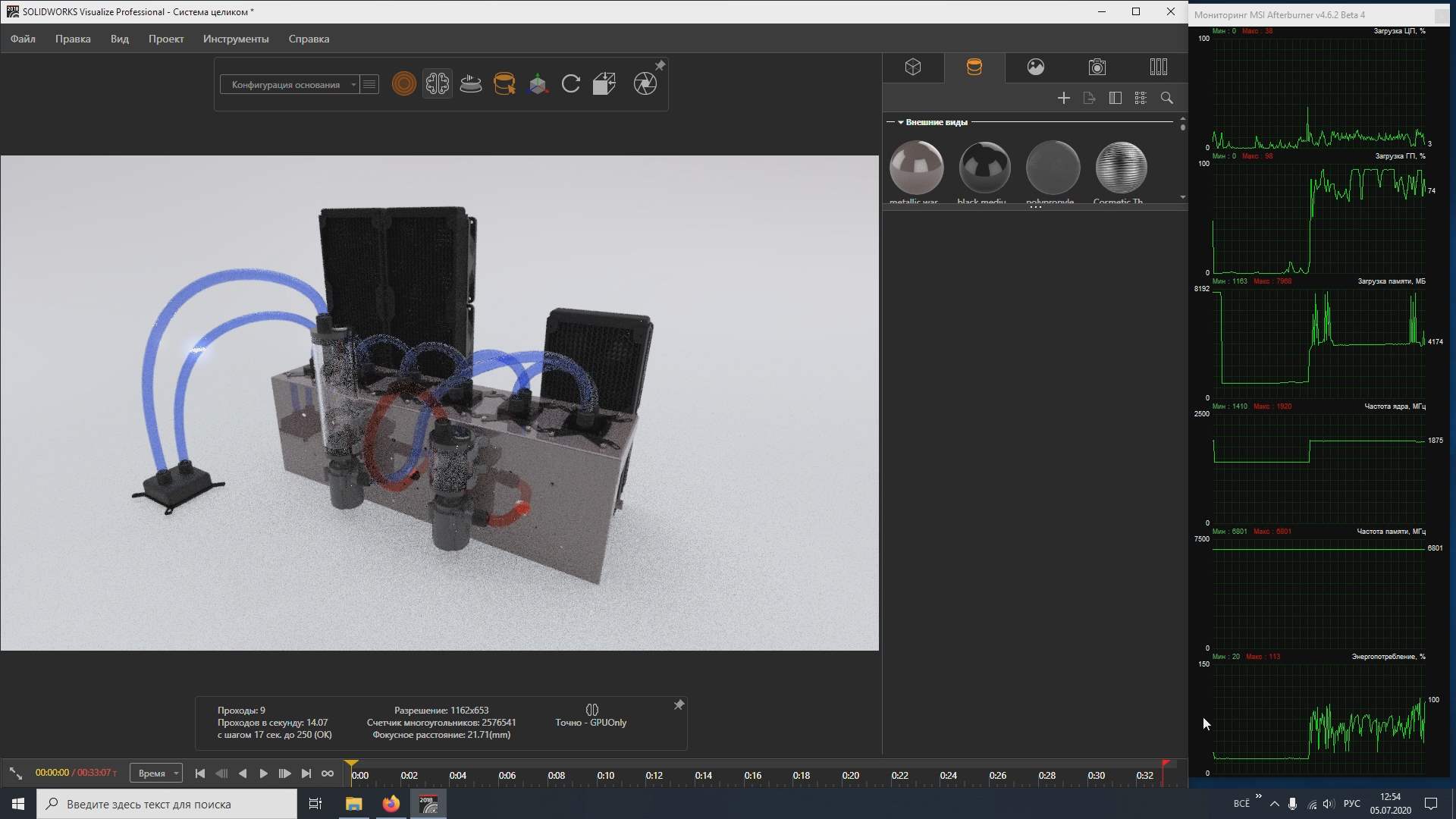
Это происходит довольно длительное время, несколько секунд, и в это время частоты не снижаются, энергопотребление тоже высокое. Из этого можно сделать вывод о том, что для работы тензорных ядер видеокарте нужно быть в 3D режиме.
Замеры производительности и разгон
Для того чтобы не высматривать доли процента я будут сравнивать не сток с разгоном, а даунклокинг с разгоном. То есть для одного из случаев занижу частоту CUDA ядер на 500 МГц, а в другом разгоню от стока на 100 МГц. И того разницу мы получим уже в 600 МГц, которую точно должно быть видно.
Память в данных тестах не разгоняется, поскольку от разгона памяти производительность улучшиться вне зависимости от изменения частот. А нам нужно понять меняется ли производительность именно от частот.
Для теста я сделал небольшую анимацию в Visualize. Выставил не очень много проходов (20) чтобы было не так долго и разрешение HD, а не FullHD.
С пониженными частотами отрисовка шла 21:38.
С повышенными частотами отрисовка шла 17:48.

Если говорить про результаты теста — очевидно, что частоты RT ядер совпадают с CUDA ядрами либо зависимы через какой-то множитель или делитель.
В общем — для рабочих задач трассировки лучей — есть смысл разгонять видеокарту. В играх, в которых значительную долю времени от общей отрисовки занимает трассировка лучей — разгон видеокарты стандартными методами также будет вносить свой вклад и в ускорение трассировки лучей.
С тензорными ядрами всё сложнее.

Напрямую измерить их производительность я не смог. Но косвенные замеры сделать мы с вами можем.
Для этого будем использовать тест в 3D Mark для DLSS.
Он показывает производительность с включенным и выключенным DLSS.
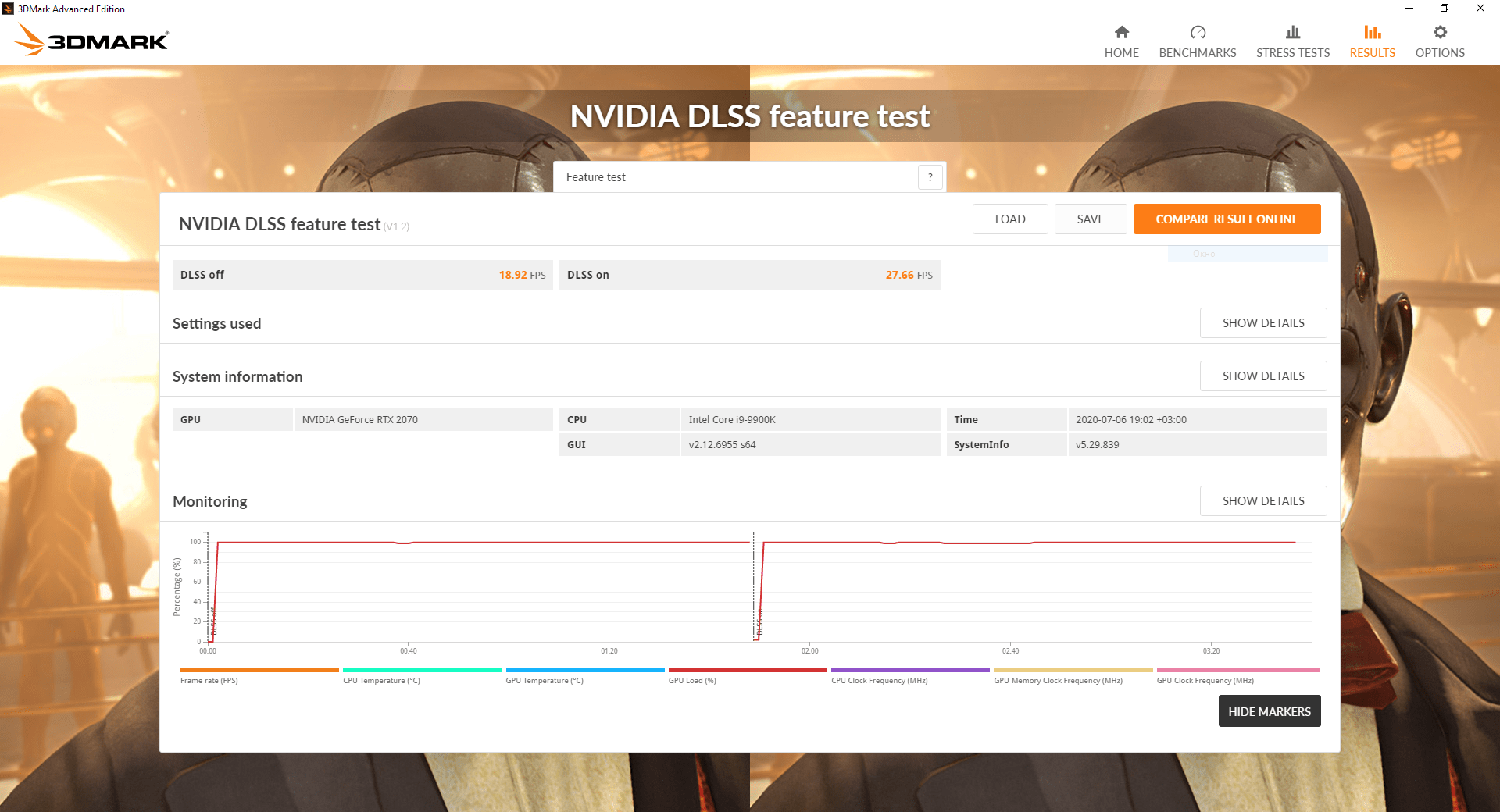
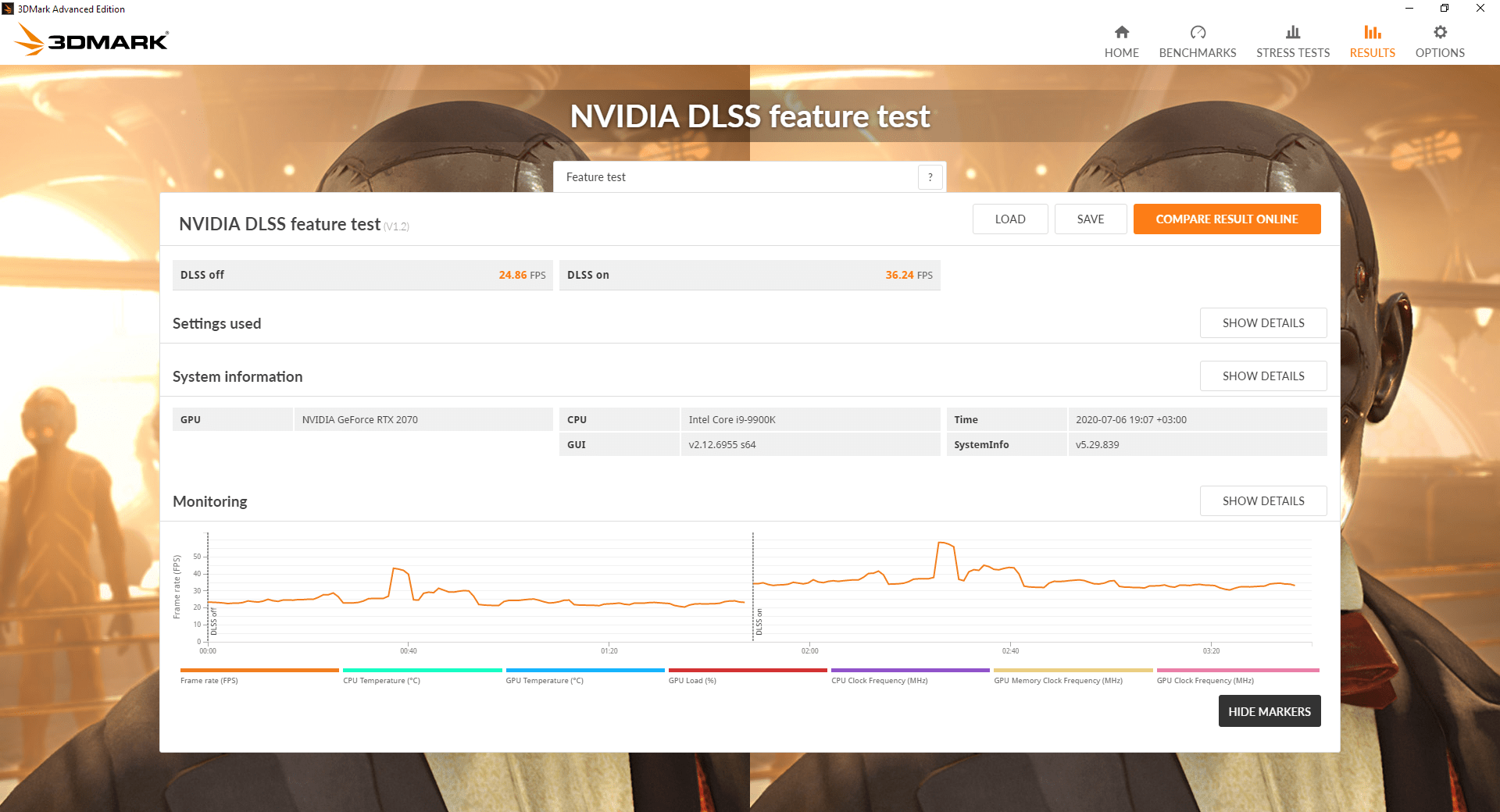
Делая тесты на двух частотах мы получим 4-ре значения производительности.

И будем анализировать их не по тем парам, что делал 3D mark, а по соответствующим парам. То есть мы будем сравнивать отношение производительностей с выключенным DLSS и со включенным DLSS.

Если пропорционально разница между сравнениями будет одинаковой или близкой к одинаковой, то можно говорить о том, что при разгоне были изменены частоты CUDA ядер и частоты тензорных ядер на равные пропорциональные величины. А вот если окажется, что разгон с выключенным DLSS повлияет на результаты существенно сильнее, чем на результаты с включенным DLSS, то можно будет сделать вывод о том, что увеличилась только производительность самой отрисовки, а время, затраченное на анализы кадра для DLSS с разными частотами осталось одно и тоже, то есть разгона тензорных ядер не было.

И были получены следующие результаты.
Из них можно получить, что без DLSS отношение производительностей системы с разгоном к системе без разгона — 1,31395.
С включенной DLSS отношение производительностей системы с разгоном к системе без разгона — 1,31019.

Расхождения не превышают погрешности тестирования. Иными словами — тензорные ядра при разгоне видеокарты тоже разгоняются.
Ну и выводы тут довольно просты. Изначально стоял вопрос — разгоняются ли RT и тензорные ядра при разгоне видеокарты. И ответ — разгоняются. И, собственно, название ползунка для разгона ядер — Core Clock для Тьрингов правильнее было бы называть SM Clock, так как разгоняются все компоненты входящие в SM модули, а не только вычислительные ядра. Другой вопрос, что частоты у тензорных и RT ядер могут не такими, как у CUDA ядер, если для них есть делители. Есть ли для них делители, к сожалению, узнать какими либо тестами мы не можем, в документации о них или их отсутствии также ничего не указано.
В общем — редко когда бывают сейчас с железками хорошие новости, но в этот раз они — хорошие. RT и тензорные ядра тоже разгоняются.
 Подписаться на канал
Подписаться на канал
