Содержание
В этой статье посмотрим на то как одноканал уменьшает скорость работы современных процессоров. Стоит напомнить, что во времена выхода DDR4 платформы с двумя каналами были у 4-х ядерных процессоров, тогда как сейчас есть 16 ядер у AMD и 10 ядер у Intel. И, естественно, шина к памяти теперь делиться на все эти ядра, тогда как и во времена 4-х ядер двухканал не был абсолютно достаточным.
Само собой производители в курсе проблемы. Так и Intel и AMD улучшают работу кеш памяти. Собственно следующее обновление AMD будет как бы минорным, то есть особо не инновационным, но благодаря трёхмерному кешу большого объёма от не самых архитектурно значимых изменений появится большой прирост в производительности. Intel же, кроме оптимизации работы с кешами, форсирует выход памяти DDR5, которая тоже немного уменьшит проблемы недостаточности двухканала для современных процессоров.
Уже есть первые тесты с DDR5 правда на диких таймингах и задержках, но в части пропускной способности — там всё сильно лучше. а для огромного числа ядер — пропускная способность это тоже очень важно, то есть надо смотреть не только на задержки.

Собственно в этой статье мы как раз и посмотрим на изменение пропускной способности, так как по задержкам разницы не будет.
Что такое каналы памяти?
Если кто не в курсе — коротко поясняю по тому что за каналы такие.
В современных процессорах контроллер оперативной памяти встроен в сам процессор и для обычных не серверных решений он имеет два канала.

То есть своего рода два независимых контроллера, каждый из которых работает со своими планками памяти. Естественно они на самом деле не независимые, так как общая адресация памяти и всё такое. Но в части работы с памятью — можно считать их раздельными.
И эта связь физическая, то есть контакты планок памяти физически приходят в разные контроллеры. Часть планок в один контроллер, часть во второй.

Ну и работают эти контроллеры параллельно, а значит и пропускная способность их работы — складывается.
Если же к одному из контроллеров память не подключена, то этот контроллер ничего и не делает.
Собственно и планки памяти зачастую продаются как раз таки комплектами по две штуки, а иногда и по 4, так как есть платформы с 4-х канальными контроллерами памяти в процессорах.
Почему изменение каналов влияет на производительность?
Дефицит данных из оперативной памяти приводит к очень нехорошим последствиям. И тут есть две нехороших вещи. Первая — это если процессор из-за голода информации не знает что ему делать. В этом случае — весь процессорный конвейер начинает пустовать, и от этого хуже удаётся заполнять исполнительные устройства. То есть падает производительность на такт, процессору нечего делать, он находится в ожиданиях задач.
Второе проявление этой проблемы — это отсутствие данных для работы. То есть что делать процессор знает, а вот значения того, с чем нужно производить операции процессору доступны только через оперативную память. В таком случае процессор периодически может допускать в исполнение то, для чего нет данных, потом это приходится повторять, есть и системы в процессоре, которые задерживают операции в очередях на выполнения. Но и очереди эти не резиновые. Так что если нет большого количества данных, то очереди просто забиваются невыполнимым для текущего момента мусором. В следствии чего падает производительность на такт. И по мониторингу точно так же это время вынужденных простоев в ожидании данных выглядит как занятое время. Естественно есть куча сложных оптимизаций как не допускать это замусоривание, но они не могут быть на 100% результативны и в их возможностях только снижение влияния на падение производительности. Но если недостаток информации катастрофический, то тут ничего уже не поможет. Процессор будет большую часть времени заниматься ничем, а при этом будут показываться какие-то проценты загрузки.
Как понять, что процессор ограничен ПСП памяти?
В общем и целом — никак, по мониторнгу это определить нельзя, но есть косвенные признаки.
Особенно это хорошо заметно в видеокартах некоторых моделей до тех поколений, где частоты динамически задаются от ограничения TDP. Там от разгона памяти увеличение энергопотребления самой памяти может составлять 2-3 Ватта, а при этом сама видеокарта начинает потреблять на 20-30 Ватт больше несмотря на то, что и до разгона памяти и после него показывалась загрузка в 100%. Просто раньше было 100%, но с простоями от ожидания информации, а после разгона памяти 100% стали с меньшими простоями. Сейчас с ограничением TPD и динамической частотой на картах от разгона памяти ситуация другая. Эффективная работа приводит к увеличению потребления из-за чего на 10-50 МГц режутся частоты ядер. Но при этом на меньших частотах видеокарта при разогнанной памяти всё равно быстрее, чем с более высокими, но с простоями от недостатка информации.
С процессорами это проявляется не так сильно и видно чаще у тех, кто вначале до предела разгоняет ядра, а после этого начинает до предела гнать память. И в этом случае чуть больший нагрев процессора от более эффективно работающей подсистемы памяти делает процессор менее стабильным в разгоне.
Ну и теперь приступим к практике.
Тестовая система
Процессор: intel i9 9900k в стоке,
Видеокарта: RTX 2070 в стоке.
Память во всех конфигурациях согласно базовому для DDR4 JEDEC стандарту на 2133 МГц. В одной группе тестов — две планки по 8 ГБ, в другой группе тестов — одна планка на 16 ГБ.
Бенчмарки.
Что касается самой памяти — для начала посмотрим на ПСП (пропускная способность памяти) и задержки.

По задержкам по цифрам есть небольшая разница, и она обусловлена тем, что на один контроллер всё таки больше нагрузки, но разница по задержкам мизерная и сильно повлиять на результаты она не может. А вот пропускная способность меняется очень сильно.
По чтению и записи падение практически двукратное.
Ну и теперь посмотрим как это отражается на производительности компьютера.
Тесты в архиваторах
Логично, что им нужны большие объёмы для работы, а значит широкая шина к памяти — это очень важно.
Win-rar

Добавление второго канала даёт прирост почти на 70%.
Возьмём другой архиватор. 7-Zip.

Тут прирост уже всего около 20%.
Бенчмарки
А есть задачи где прироста нет в принципе, то есть задача оптимизирована так, что максимально эффективно использует кеш процессора.
Например Cinebench R15.

Что с двумя, что с одним каналом — разницы в результатах — нет.
В общем — где-то есть огромная разница, а где-то её нет вообще.
Тесты в играх
Теория по играм
Ну и главный вопрос — к чему относятся игры. К той задаче, где есть разница или где её нет.
Понятное дело, что тут важна практика, но давайте всё таки цепанём немного теории.
В целом — процесс обработки игры для процессора можно разделить на два этапа:

Первый — просчёт игрового движка, то есть каждый кадр есть какая-то физика игровая, и периодически нужно отрабатывать какие-то алгоритмы сценария мира.
За имитацию обсчётов у нас будет CPU тест в 3D Mark.
В тесте анимация происходит не за счёт отрисовки элементов, а за счёт просчёта положения частиц.

В этом тесте разницы между системами — нет. Это, конечно, не значит, что это характерно для всех игр. Но в целом — для игровой физики не надо большого количества данных, вероятно тут кеша процессора было достаточно для того чтобы хватало и половины ширины шины.
Но это только первая часть работы процессора.
Вторая часть — это работа процессора на этапе отрисовки, то есть обработка вызовов на отрисовку для совместной работы с видеокартой.

Тут нам поможет тест 3D Mark API бенчмарк.
Он делает тесты в DX11, DX11 мультипоточном, DX 12 и Вулкане.

Начнём с однопоточного DX11.
Тут видно небольшое преимущество у двухканала. Вообще у теста большая погрешность — процентов 10. И в целом — можно сказать, что результаты в эту погрешность укладываются.
Дальше у нас DX11 мультипоток.
Тут уже точно это не погрешность. От двухканала прирост больше 35%.
Ну оно и логично. Одному ядру хватало ширины и половины от возможной, а вот 8-ми ядрам уже этого не хватает.
Однако — у этих вызовов на старых API есть свои задержки, собственно которые и устранятся в новых API. И из-за врождённых задержек — задержки от памяти становятся не столь критичными.
В новых API ситуация уже кардинально отличается.
На 12 DX прирост от второго канала — 80%
На вулкане прирост около 75%.
В общем — разница почти двукратная.
Что касается практики — стоит понимать, что и алгоритмы с обсчётами могут быть менее оптимизированы, но и в играх вызовов на отрисовку не так много, как в бенчмарке.
Но главное отличие, конечно, ещё и в том, что данные в видеопамять поступают через северный мост процессора. То есть в моменты, когда идёт подгрузка текстур ширина канала ещё сильнее начинает ограничивать производительность процессора.

Этот процесс в бенчмарках сложно было бы подловить. Но думаю все знакомы с какими-то подлагами игры на подгрузках и с одноканалом эти подлагивания будут сильнее.
И, конечно, результаты будут зависеть и от видеокарты. У меня в тесте 8-ми гиговая RTX 2070, и она реже производит какие-то подгрузки данных. Была бы в тесте 2-х гиговая, она бы постоянно лила свой трафик данных через северный мост процессора к памяти, и ухудшала бы работу процессора при голоде памяти.
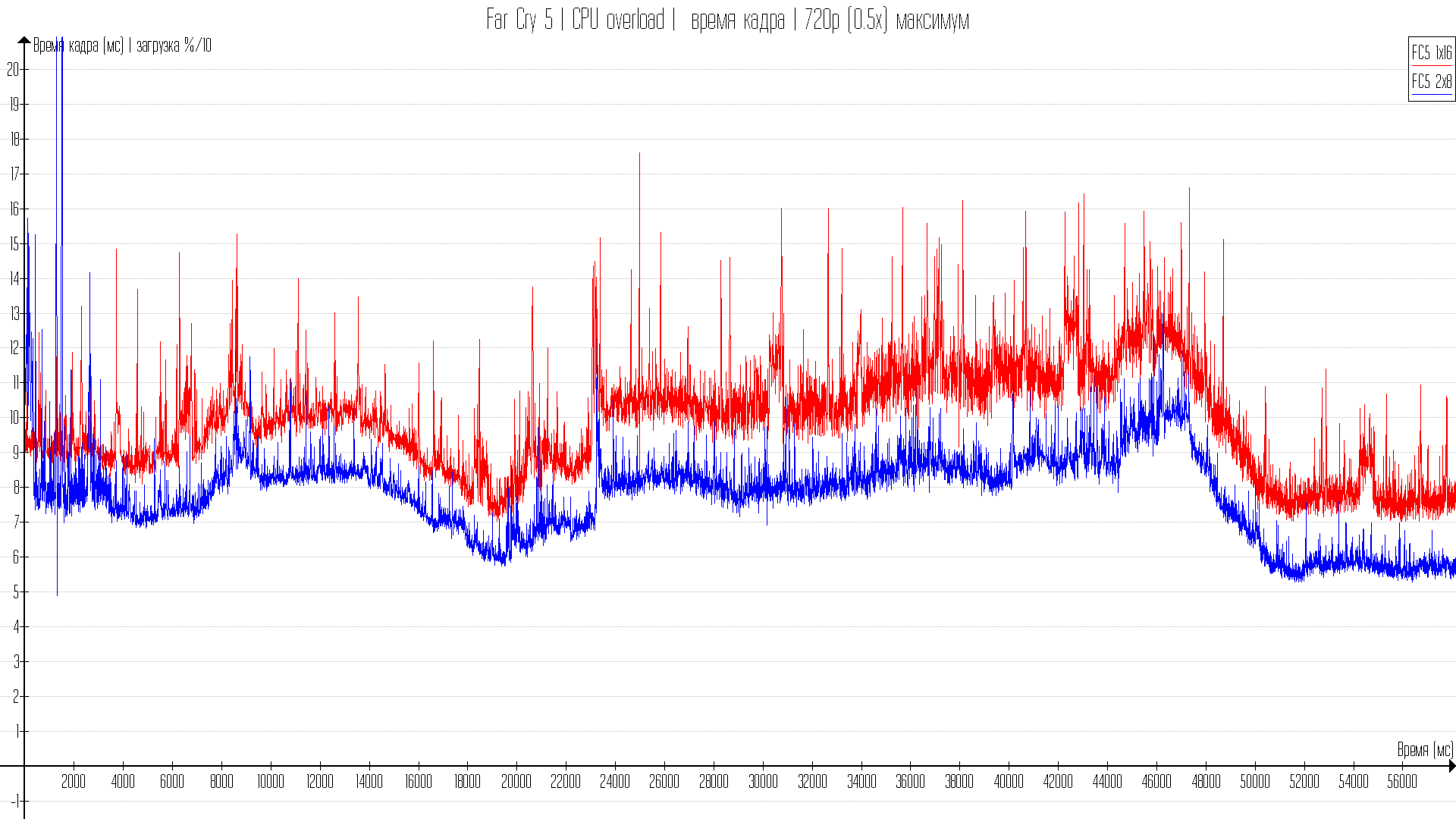
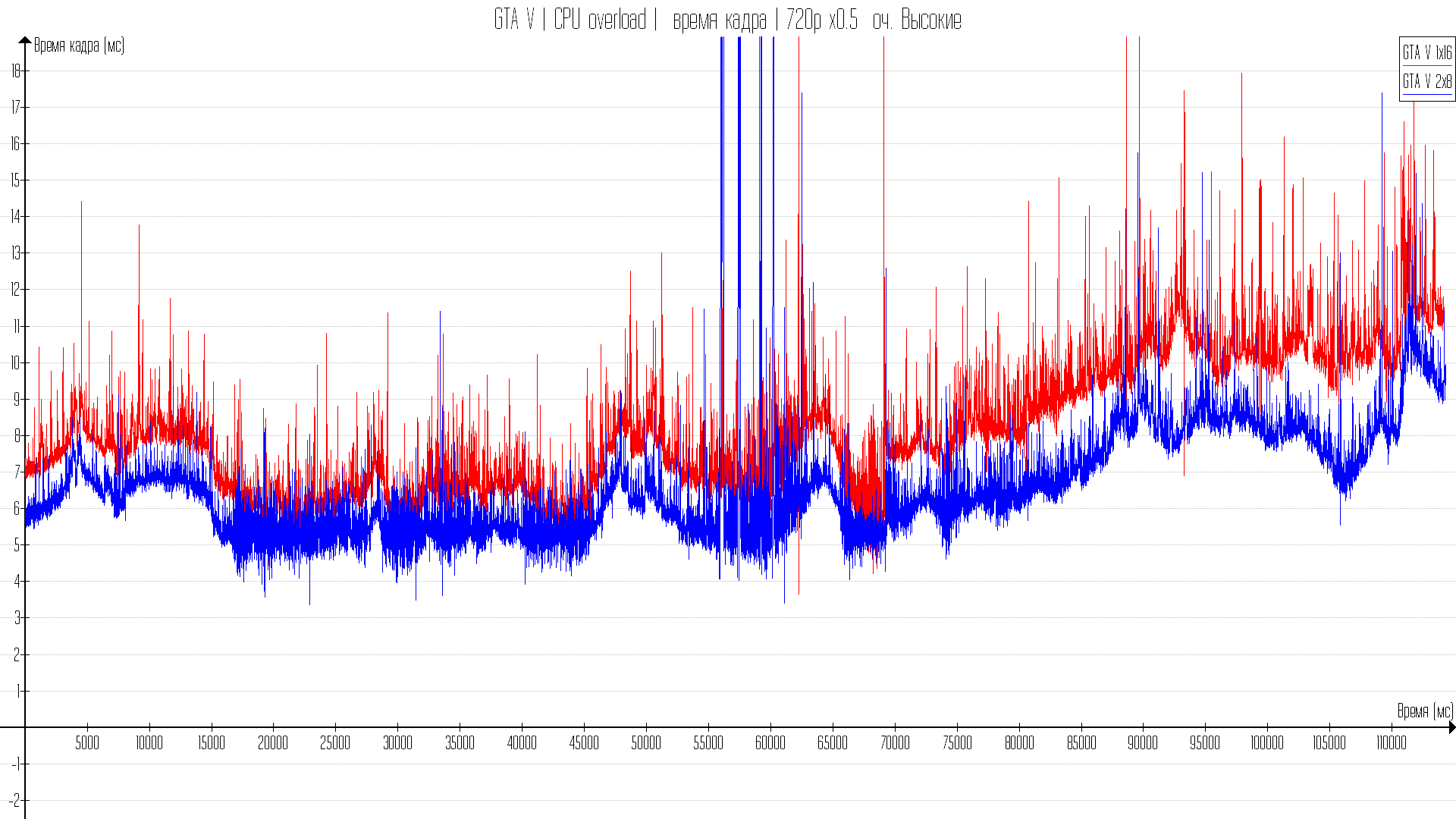
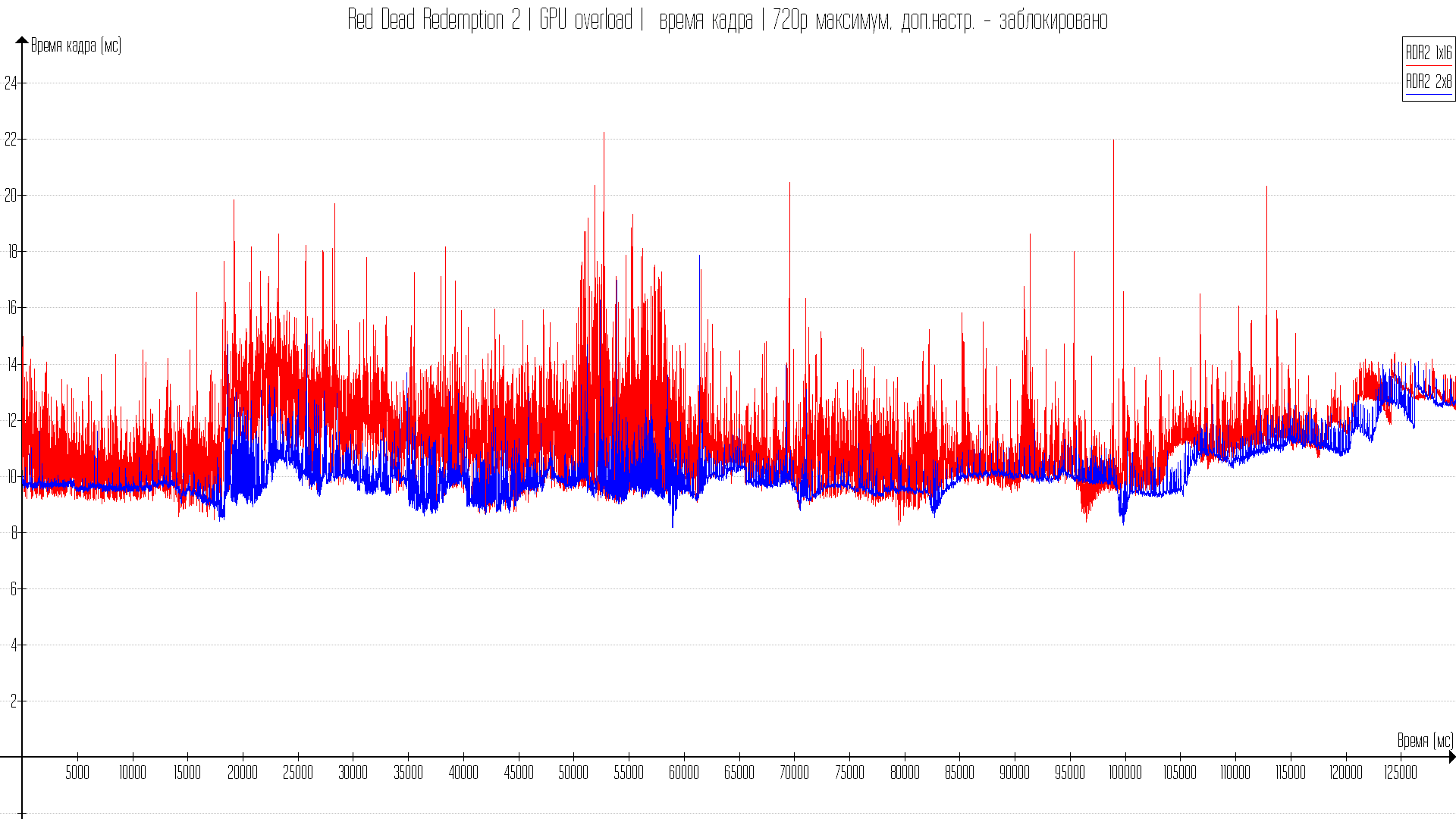
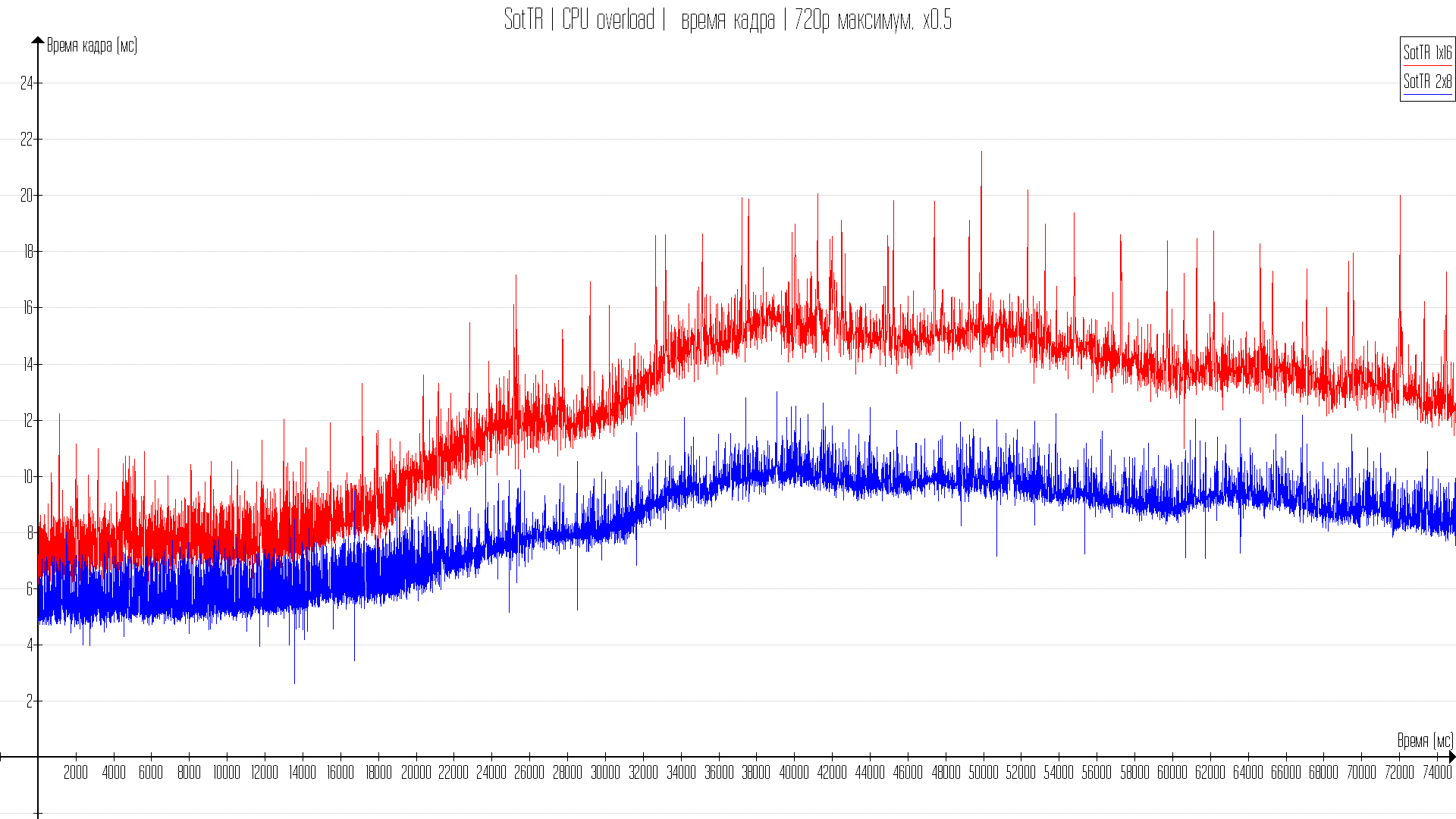
Практические тесты в играх
Игр в тест я взял не много, но выбрал на разных движках и API. Есть на 11DX, есть на 12 и есть на вулкане. Всего игр 4. Во всех играх стоят максимальные настройки, но со сниженным разрешением рендеринга.
С 8-ми гиговой картой, когда данные для видеокарты не кешируются в оперативной памяти разница от одного или двухканала будет только при ограничении производительности процессора. Но, собственно, те тесты что будут показывать AMD презентуя большой кеш и Intel показывая прирост на такт в играх — будут показываться также с ограничением в процессор.
В тестах важно рассматривать как изменяются показатели в динамики в зависимости от текущей сцены, так что этот раздел статьи стоит смотреть в видео версии:
Выводы
И естественно, что чем больше ядер и чем они быстрее — тем выше требования к ширине шины к оперативной памяти. Но многое зависит и от задачи, в которой производится сравнение. Внутри одной и той же игры разница тоже очень сильно зависит от происходящего конкретно в текущий момент, поэтому назвать какую-то конкретную цифру влияния — не получится. Так же надо понимать, что в этом тесте и двухканал не был каким-то заоблачным, так как была стоковая память, и хороший разгон памяти ещё даст прирост до 15-20% в некоторых задачах. Собственно и большой кеш и переход на DDR5 как раз и смогут отбить эти самые проценты, и вдобавок сделать не бессмысленным дальнейший рост производительности ядер и увеличение их числа. Ну и так же — если вы заходили в статью с целью понять — стоит ли экономить на двухканале — очевидно, что не стоит. Прирост на десятки процентов, а разница по цене всей сборки компьютера от двух планок вместо одной единицы процентов.
 Подписаться на канал
Подписаться на канал

